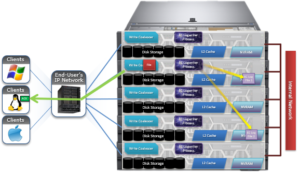
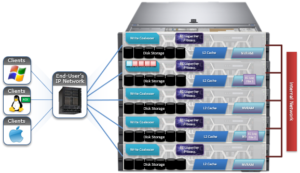
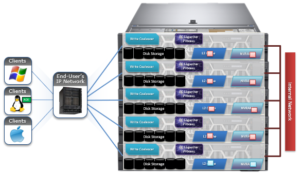
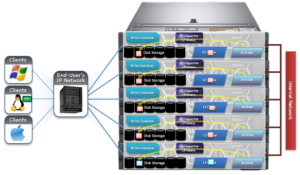
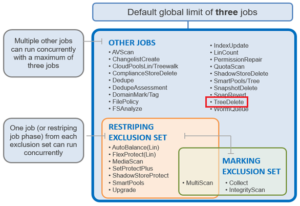
In OneFS, the Groupnet networking object, is an integral part of multi-tenancy support.
Multi-Tenancy, within the SmartConnect context, refers to the ability of a OneFS cluster to simultaneously handle more than one set of networking configuration. Multi-Tenant Resolver or MTDNS refers to the subset of that feature pertaining specifically to hostname resolution against DNS nameservers.
Groupnets sit above existing objects, subnets and address pools, in the object hierarchy. Groupnets may contain one or more subnets, and every subnet exists within one (and only one) groupnet.
All newly configured and upgraded clusters start out with one default groupnet named groupnet0. Customers who any not interested in multi-tenancy will simply use this single groupnet and never make any others.
Groupnets are the configuration point for DNS settings, which had previously been global to the cluster. Nameservers and other DNS options are now properties of the groupnet object, and configured there in the CLI isi network groupnets and WebUI. Conceptually it would be appropriate to think of groupnets as a networking tenant; different groupnets are used to allow portions of the cluster to have different networking properties for name resolution, etc. The recommendation is to create a groupnet for each different DNS namespace that’s required.
Note that OneFS also has a networking object termed a netgroup, used to manage network access. Groupnets are unrelated to netgroups.
The DNS cache is also multi-tenant-aware, so it maintains separate instances for individual groupnets. Each groupnet may specify whether to enable caching or not: It’s enabled by default, and this is the recommended setting for both performance and reliability.
A number of global cache timeout settings are also available. The CLI for managing them is isi network dnscache, and more detail is available via the isi-network(8) manpage. Note, the isi_cbind command retains the same syntax and usage.
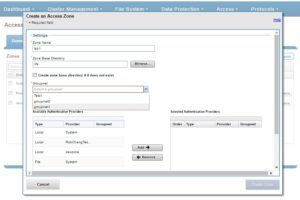
Access Zones and groupnets are tightly coupled, and must be specified at zone creation. Zones may only be associated with address pools and authentication providers that share the same groupnet. For example, the following command creates an access zone with groupnet association:
# isi zone zones create lab1 /ifs/data/lab1 –groupnet groupnet1
Or from the WebUI:
In a multi-tenant environment, authentication providers (AD, LDAP, etc) need to know which networking properties they should use, and therefore need to be bound to a groupnet. This happens directly at creation time. A groupnet may be specified via the CLI using the create option –groupnet. Or, if unspecified, the default groupnet0 will be assumed. For example:
# isi auth ads create lab.isilon.com Administrator –groupnet groupnet1
Or via the WebUI:
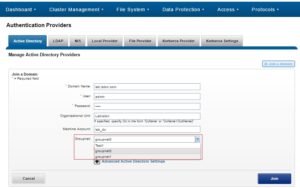
Once created, authentication providers may only be used by access zones within the same groupnet. If a provider is created and associated with the wrong groupnet, it must be deleted and re-created with the correct one.
In general, services or protocols which work face end users and are access-zone aware are also supported with Groupnets. Administrative and infrastructure services like WebUI, SSH, SyncIQ, and so on are not.
When creating new network tenants, the recommended process is:
- Groupnet, create and specify nameservers
- Access zone, create and associate with groupnet (which must already be created)
- Subnet, create within groupnet (which must already be created)
- Address pool, create within subnet (which must already be created) and associate with access zone (which must already be created)
- Authentication provider, create and associate with groupnet (which must already be created)
- Access zone, modify to add authentication provider
Attempting to do things out of this order may create other challenges. For example, if an access zone has not already been created in a groupnet, you will be unable to add an address pool, since it requires an access zone to already be present.
Some customers have a set of host information they want available without DNS and instead wish to specify locally on the cluster. A file /etc/local/hosts can be created for specifying network hosts manually, and, by default, any entries it contains will be used in groupnet0. However, additional groupnets can also be listed in square brackets. The lines that follow each will be used to populate a hosts file specific to that groupnet. For example:
# cat /etc/local/hosts 1.2.3.4 hosta.foo.com # default groupnet0 1.2.3.5 hostb.foo.com # default groupnet0 [groupnet1] 5.6.7.8 hostc.bar.com # groupnet1 5.6.7.9 hostd.bar.com # groupnet1
Please be aware of the following considerations:
- Despite using different nameservers, the address space is still assumed to be unique. OneFS does not permit IP address conflicts even if the conflicting addresses are in different groupnets.
- Names of authentication providers also must be unique, even across groupnets. You cannot, for example, have two AD providers joined to the same domain name even if they are in different groupnets (and therefore the same name may resolve to different addresses and machines.)
- It is permissable to have a configuration wherein some nodes are unable to route to nameservers of some groupnets, although that practice is not recommended for the default groupnet. In this case all tasks associated with these limited groupnets, including CLI and WebUI administration, must be performed on nodes that are capable of these lookups.
So, the SmartConnect hierarchy encompasses the following network objects:
- Groupnet: Represents a ‘network tenant and can contain a collection of subnets’. It also contains information about DNS resolution of external authentication providers.
- Subnet: Contains a netmask and an IP base address, together which define a range of IP addresses. A subnet can be either IPv4 or IPv6. A subnet contains a collection of IP pools.
- IP Pool: An IP Pool is an object that contains a set of IP addresses within a subnet and configuration on how they are used. An IP Pool can be associated with a set of DNS host names. An IP pool may be either static or dynamic, based on the –alloc-method setting on the IP Pool. This attribute indicates whether the IPs in the pool can move back and forth between nodes when a node goes down.
- Network Rule: A network rule contains specifications on how to auto-populate a pool with interfaces. For example, a rule could specify that the pool contains the ext-1 interface on all nodes. If a pool contains more than one network rule, they are considered additive.
Network objects are specified by their network ID, which is a series of network name identifiers separated by either periods or colons.
To create a SmartConnect groupnet and configure DNS client settings, run the isi network groupnet create command. For example, the following command creates a groupnet and adds a DNS server with caching enabled:
# isi network groupnet create groupnet1 --dns-servers=192.168.10.10 --dns-cache-enabled=true
Or via the WebUI:
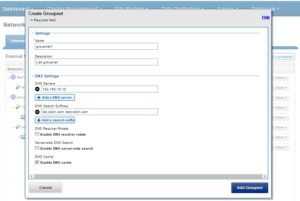
Unless it’s the default, a groupnet can be fairly easily removed from SmartConnect. However, if a groupnet is associated with an access zone, removing it may adversely impact other areas of the cluster config. The recommended order for removing a groupnet is:
- Delete IP address pools in subnets associated with the groupnet.
- Delete subnets associated with the groupnet.
- Delete authentication providers associated with the groupnet.
- Delete access zones associated with the groupnet.
To delete a groupnet, run:
# isi network groupnet delete <groupnet_name>
Note that in several cases, the association between a groupnet and another OneFS component, such as access zones or authentication providers, is absolute and can’t be modified to associate it with another groupnet. For example, the following command unsuccessfully attempts to delete groupnet1 which is still associated with an access zone:
# isi network modify groupnet groupnet1
Groupnet groupnet1 is not deleted; groupnet can’t be deleted while pointed at by zone(s) zoneB
To modify groupnet attributes, including the name, supported DNS servers, and DNS configuration settings, run the isi network groupnet modify command. For example:
# isi network groupnet modify groupnet1 –dns-search=lab.isilon.com,test.isilon.com
To retrieve and sort a list of groupnets by ID in descending order, run the isi network groupnets list command. For example:
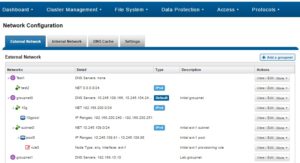
# isi network groupnets list --sort=id --descending ID DNS Cache DNS Search DNS Servers Subnets ------------------------------------------------------------ groupnet2 True lab.isilon.com 192.168.2.75 subnet2 192.168.2.67 subnet4 groupnet1 True 192.168.2.92 subnet1 192.168.2.83 subnet3 groupnet0 False 192.168.2.11 subnet0 192.168.2.20 -------- Total: 3 To view the details of a specific groupnet, run the isi network groupnets view command. For example: # isi network groupnets view groupnet1 ID: groupnet1 Name: groupnet1 Description: Lab storage groupnet DNS Cache Enabled: True DNS Options: - DNS Search: lab.isilon.com DNS Servers: 192.168.1.75, 172.16.2.67 Server Side DNS Search: True Allow Wildcard Subdomains: True Subnets: subnet1, subnet3 Groupnet information can also be viewed, created, deleted and modified from the WebUI by navigating to: Cluster Management -> Network Configuration -> External Network
So there we have it. The groupnet is the networking cornerstones of the OneFS multi-tenancy stack.
The OneFS protocols and services which are multi-tenant aware and can work with multiple groupnets include:
- SMB
- NFS (including NSM and NLM)
- HDFS
- S3
- Authentication (AD, LDAP, NIS, Kerberos)