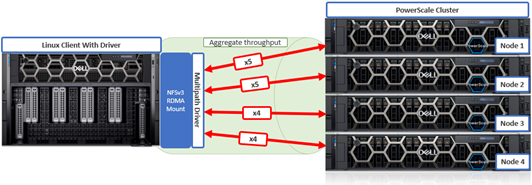
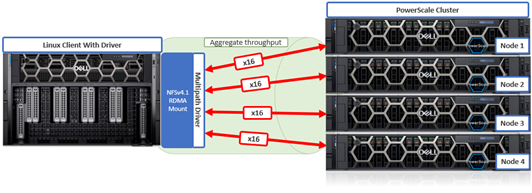
In this second article in this series, we take a closer look at the management and monitoring of OneFS Pre-upgrade Healthchecks.
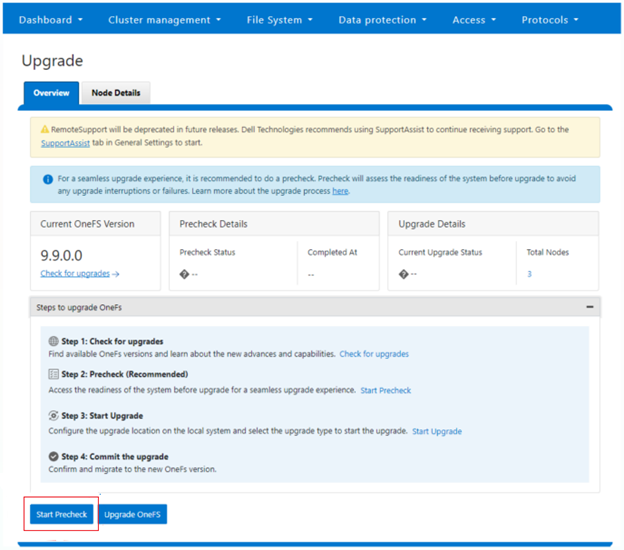
When it comes to running pre-upgrade checks, there are two execution paths: Either as the precursor to an actual upgrade, or as a stand-alone assessment. As such, the general workflow for the upgrade pre-checks in both assessment and NDU modes is as follows:
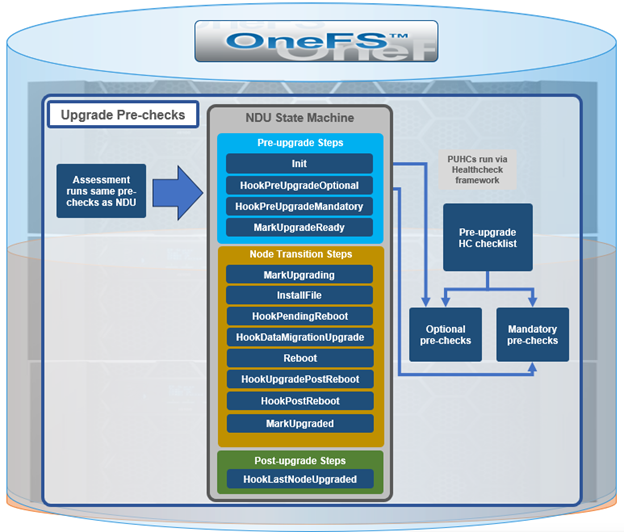
The ‘optional’ and ‘mandatory’ hooks of the Upgrade framework queue up a pre-check evaluation request to the HealthCheck framework. The results are then stored in an assessment database, which allows a comprehensive view of the pre-checks.
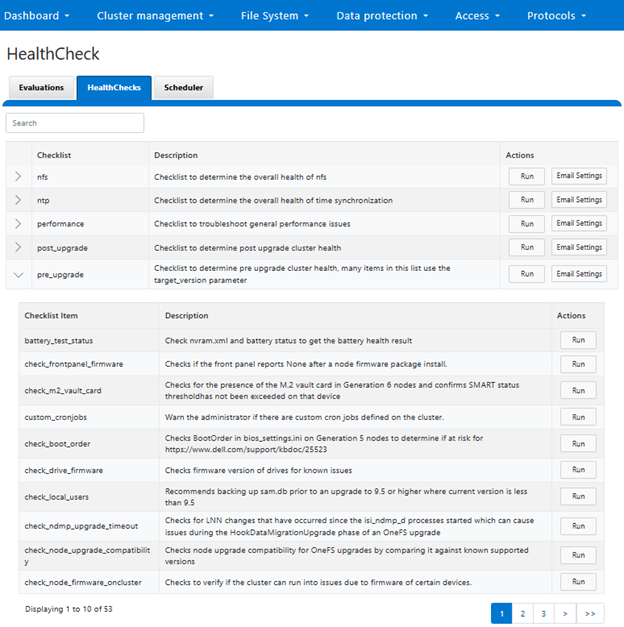
As of OneFS 9.9, the list of pre-upgrade checks include:
| Checklist Item | Description |
| battery_test_status | Check nvram.xml and battery status to get the battery health result |
| check_frontpanel_firmware | Checks if the front panel reports None after a node firmware package install. |
| check_m2_vault_card | Checks for the presence of the M.2 vault card in Generation 6 nodes and confirms SMART status threshold has not been exceeded on that device |
| custom_cronjobs | Warn the administrator if there are custom cron jobs defined on the cluster. |
| check_boot_order | Checks BootOrder in bios_settings.ini on Generation 5 nodes to determine if at risk for https://www.dell.com/support/kbdoc/25523 |
| check_drive_firmware | Checks firmware version of drives for known issues |
| check_local_users | Recommends backing up sam.db prior to an upgrade to 9.5 or higher where current version is less than 9.5 |
| check_ndmp_upgrade_timeout | Checks for LNN changes that have occurred since the isi_ndmp_d processes started which can cause issues during the HookDataMigrationUpgrade phase of an OneFS upgrade |
| check_node_upgrade_compatibility | Checks node upgrade compatibility for OneFS upgrades by comparing it against known supported versions |
| check_node_firmware_oncluster | Checks to verify if the cluster can run into issues due to firmware of certain devices. |
| check_security_hardening | Check if the security hardening (FIPS and STIG mode) is applied on the cluster. |
| check_services_monitoring | Checks that enabled services are being monitored. |
| check_upgrade_agent_port | Checks the port used by the isi_upgrade_agent_d daemon to ensure it is not in use by other processes |
| check_upgrade_network_impact | Checks for the risk of inaccessible network pools during a parallel upgrade |
| check_cfifo_thread_locking | Checks if node may be impacted by DTA000221299, cluster deadlocking from Coalescer First In First Out (CFIFO) thread contention |
| ftp_root_permissions | Checks if FTP is enabled and informs users about potential FTP login issues after upgrading. |
| flex_protect_fail | Warns if the most recent FlexProtect or FlexProtectLin job failed. |
| files_open | Checks for dangerous levels of open files on a node. |
| ifsvar_acl_perms | Checks ACL permissions for ifsvar and ifsvar/patch directory |
| job_engine_enabled | Service isi_job_d enabled |
| mediascan_enabled | Determines if MediaScan is enabled. |
| mcp_running_status | Status of MCP Process. |
| smartconnect_enabled | Determines if SmartConnect enabled and running. |
| flexnet_running | Determines if Flexnet is running. |
| opensm_masters | Determines if backend fabric has proper number of opensm masters. |
| duplicate_gateway_priorities | Checks for subnets with duplicate gateway priorities. |
| boot_drive_wear | Boot drive wear level. |
| dimm_health_status | Warns if there are correctable DIMM Errors on Gen-4 and Gen-6. |
| node_capacity | Check the cluster and node pool capacity. |
| leak_freed_blocks | Check if the sysctl ‘efs.lbm.leak_freed_blocks’ is set to 0 for all nodes. |
| reserve_blocks | Check if the sysctl ‘efs.bam.layout.reserved_blocks’ is set to the default values of 32000 for all nodes. |
| root_partition_capacity | Check root (/) partition capacity usage. |
| var_partition_capacity | Check ‘/var’ partition capacity usage. |
| smb_v1_in_use | Check to see if SMBv1 is enabled on the cluster. If it is enabled, provide an INFO level alert to the user. Also check if any current clients are usingSMBv1 if it is enabled and provide that as part of the alert. |
| synciq_daemon_status | Check if all SyncIQ daemons are running. |
| synciq_job_failure | Check if any latest SyncIQ job report shows failed and gather the failure infos. |
| synciq_job_stalling | Checks if any running SyncIQ jobs are stalling. |
| synciq_job_throughput | Check if any SyncIQ job is running with non-throughput. |
| synciq_pworker_crash | Check if any pworker crash, related stack info, generates when the latest SyncIQ jobs failed with worker crash errors. |
| synciq_service_status | Check if SyncIQ service isi_migrate is enabled. |
| synciq_target_connection | Check SyncIQ policies for target connection problems. |
| system_time | Check to warn if the system time is set to a time in the far future. |
| rpcbind_disabled | Checks if rpcbind is disabled, which can potentially cause issues on startup |
| check_ndmp | Checks for running NDMP sessions |
| check_flush | Checks for running flush processes / active pre_flush screen sessions |
| battery_test_status | Check nvram.xml and battery status to get the battery health result |
| checkKB516613 | Checks if any node meets criteria for KB 000057267 |
| check_flush | Checks for running flush processes / active pre_flush screen sessions |
| upgrade_blocking_jobs | Checks for running jobs that could impact an upgrade |
| patches_infra | Warns if INFRA patch on the system is out of date |
| check_flush | Checks for running flush processes / active pre_flush screen sessions |
| cloudpools_account_status | Cloud Accounts showing unreachable when installing 9.5.0.4(PSP-3524) or 9.5.0.5 (PSP-3793) patch |
| nfs_verify_riptide_exports | Verify the existence of nfs-exports-upgrade-complete file. |
| upgrade_version | Pre-upgrade check to warn about lsass restart. |
In OneFS 9.8 and earlier, the upgrade pre-check assessment CLI command set did not provide a method for querying the details.
To address this, OneFS 9.9 now includes the ‘isi upgrade assess view’ CLI syntax, which displays a detailed summary of the error status and resolution steps for any failed pre-checks. For example:
# isi upgrade assess view PreCheck Summary: Status: Completed with warnings Percentage Complete: 100% Started on: 2024-11-05T00:27:50.535Z Check Name Type LNN(s) Message ---------------------------------------------------------------------------------------------------------------------------------------------------------------- custom_cronjobs Optional 1,3 Custom cron jobs are defined on the cluster. Automating tasks on a PowerScale cluster is most safely done with a client using the PowerScale OneFS API to access the cluster. This is particularly true if you are trying to do some type of monitoring task. To learn more about the PowerScale OneFS API, see the OneFS API Reference for your version of OneFS. Locations of modifications found: /usr/local/etc/cron.d/ ---------------------------------------------------------------------------------------------------------------------------------------------------------------- Total: 1
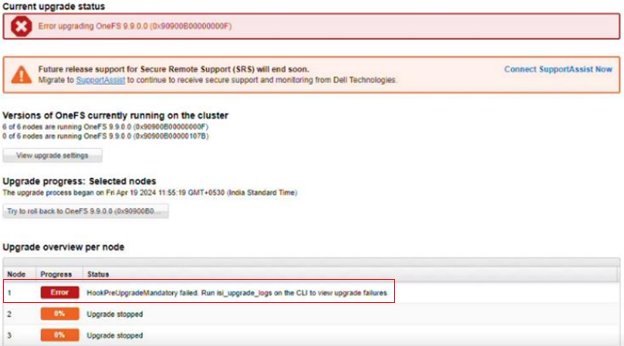
In the example above, the assessment view of a failed optional precheck is flagged as a warning. Whereas a failed mandatory precheck is logged as an error and upgrade blocked with the following ‘not ready to upgrade’ status. For example:
# isi upgrade assess view PreCheck Summary: Status: Completed with errors - not ready for upgrade Percentage Complete: 100% Completed on: 2024-11-02T21:44:54.938Z Check Name Type LNN(s) Message ---------------------------------------------------------------------------------------------------------------------------------------------------------------- ifsvar_acl_perms Mandatory - An underprivileged user (not in wheel group) has access to the ifsvar directory. Run 'chmod -b 770 /ifs/.ifsvar' to reset the permissions back to the default permissions to resolve the security risk. Then, run 'chmod +a# 0 user ese allow traverse /ifs/.ifsvar' to add the system-level SupportAssist User back to the /ifs/.ifsvar ACL. ---------------------------------------------------------------------------------------------------------------------------------------------------------------- Total: 1
Here, the pre-check summary both alerts to the presence of insecure ACLs on a critical OneFS directory, while also provides comprehensive remediation instructions. The upgrade could not proceed in this case due to a mandatory pre-check failure.
A OneFS upgrade can be initiated with the following CLI syntax:
# isi upgrade cluster start --parallel -f /ifs/install.isi
If a pre-check fails, the upgrade status can be checked with the ‘isi upgrade view’ CLI command. For example:
# isi upgrade view Upgrade Status: Current Upgrade Activity: OneFS upgrade Cluster Upgrade State: error (see output of isi upgrade nodes list) Upgrade Process State: Stopped Upgrade Start Time: 2024-11-03T15:12:20.803000 Current OS Version: 9.9.0.0_build(1)style(11) Upgrade OS Version: 9.9.0.0_build(4299)style(11) Percent Complete: 0% Nodes Progress: Total Cluster Nodes: 3 Nodes On Older OS: 3 Nodes Upgraded: 0 Nodes Transitioning/Down: 0 A Pre-upgrade check has failed please run “isi upgrade assess view” for results. If you would like to retry a failed action on the required nodes, use the command “isi upgrade cluster retry-last-action –-nodes”. If you would like to roll back the upgrade, use the command “isi upgrade cluster rollback”. LNN Version Status ------------------------------------------------------------------------------ 9.0.0 committed
Note that, in addition to retry and rollback options, the above output recommends running the ‘isi upgrade assess view’ CLI command to see the specific details of the failed pre-check(s). For example:
# isi upgrade assess view PreCheck Summary: Status: Warnings found during upgrade Percentage Complete: 50% Completed on: 2024-11-02T00:11:21.705Z Check Name Type LNN(s) Message ---------------------------------------------------------------------------------------------------------------------------------------------------------------- custom_cronjobs Optional 1-3 Custom cron jobs are defined on the cluster. Automating tasks on a PowerScale cluster is most safely done with a client using the PowerScale OneFS API to access the cluster. This is particularly true if you are trying to do some type of monitoring task. To learn more about the PowerScale OneFS API, see the OneFS API Reference for your version of OneFS. Locations of modifications found: /usr/local/etc/cron.d/ ---------------------------------------------------------------------------------------------------------------------------------------------------------------- Total: 1
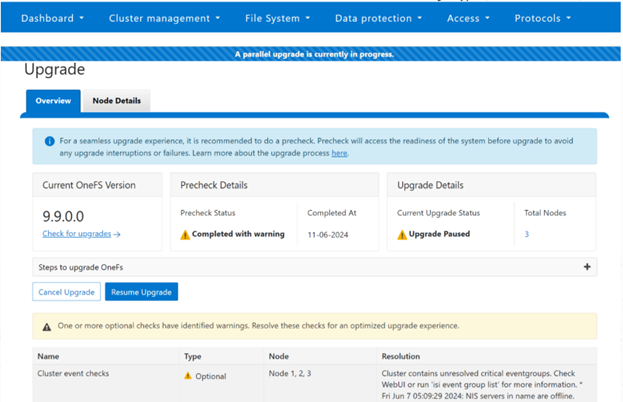
In the above, the pre-check summary alerts of a failed optional check, due to the presence of custom (non default) crontab entries in the cron job’s schedule. In this case, the upgrade can still proceed, if desired.
While OneFS 9.8 and earlier releases do have the ability to skip the optional pre-upgrade checks, this can only be configured prior to the upgrade commencing:
# isi upgrade start –skip-optional ...
However, OneFS 9.9 provides a new ‘skip optional’ argument for the ‘isi upgrade retry-last-action’ command, allowing optional checks to also be avoided while an upgrade is already in process:
# isi upgrade retry-last-action –-skip-optional ...
The ‘isi healthcheck evaluation list’ CLI command can also be useful for reporting pre-upgrade checking completion status. For example:
# isi healthcheck evaluation list ID State Failures Logs --------------------------------------------------------------------------------------------------------------------------------------------------- ------------------------ pre_upgrade_optional20240508T1932 Completed - Fail WARNING: custom_cronjobs (1-4) /ifs/.ifsvar/modules/health check/results/evaluations/pre_upgrade_optional20240508T1932 pre_upgrade_mandatory20240508T1935 Completed - Pass - /ifs/.ifsvar/modules/healthcheck/results/evaluations/pre_upgrade_mandatory20240508T1935 --------------------------------------------------------------------------------------------------------------------------------------------------- ------------------------ Total: 2
In the above example, the mandatory pre-upgrade checks all pass without issue. However, a warning is logged, alerting of an optional check failure due to the presence of custom (non default) crontab entries. More details and mitigation steps for this check failure can be obtained by running ‘isi assess view’ CLI command. In this case, the upgrade can still proceed, if desired.