In the previous article in this Dell Technologies Connectivity Services (DTCS) for OneFS Support series, we reviewed the off-cluster prerequisites for enabling DTCS on a PowerScale cluster:

- Upgrading the cluster to OneFS 9.10 or later.
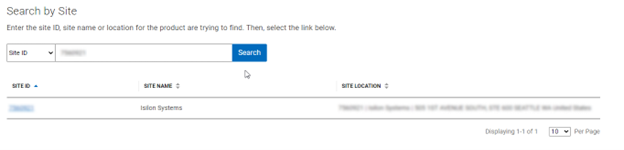
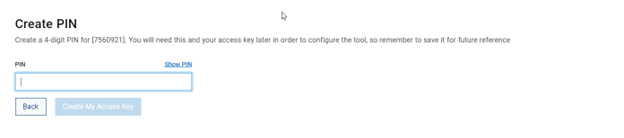
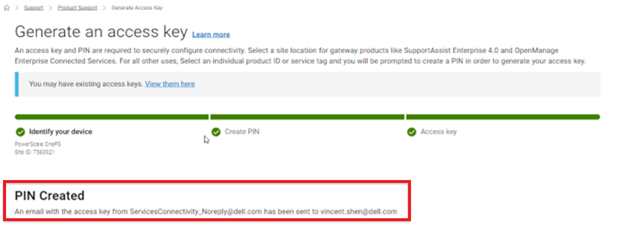
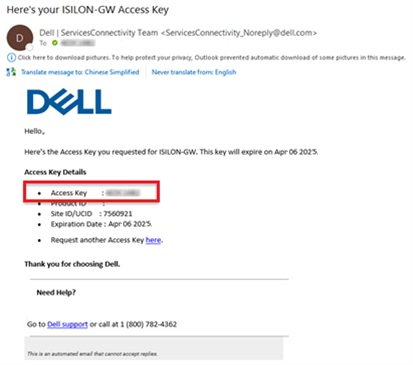
- Obtaining the secure access key and PIN.
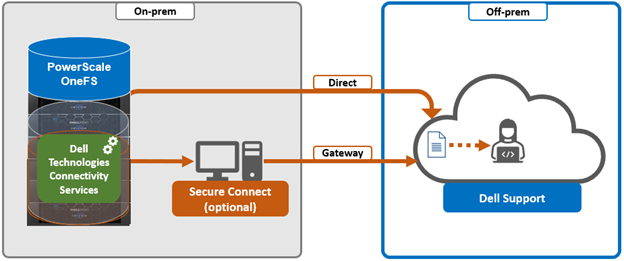
- Selecting either direct connectivity or gateway connectivity.
- If using gateway connectivity, installing Secure Connect Gateway v5.x.
In this article, we turn our attention to step 5 – provisioning Dell Technologies Connectivity Services (DTCS) on the cluster.
Note that, as part of this process, we’ll be using the access key and PIN credentials previously obtained from the Dell Support portal in step 2 above.
Provisioning DTCS on a cluster

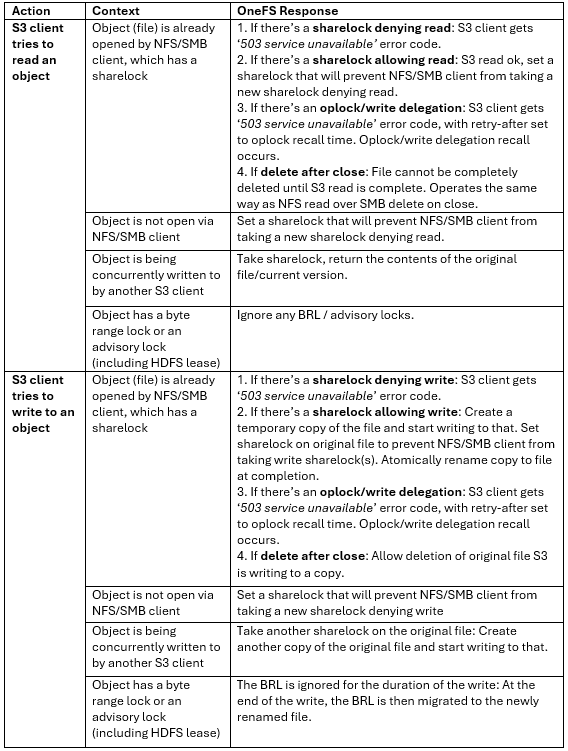
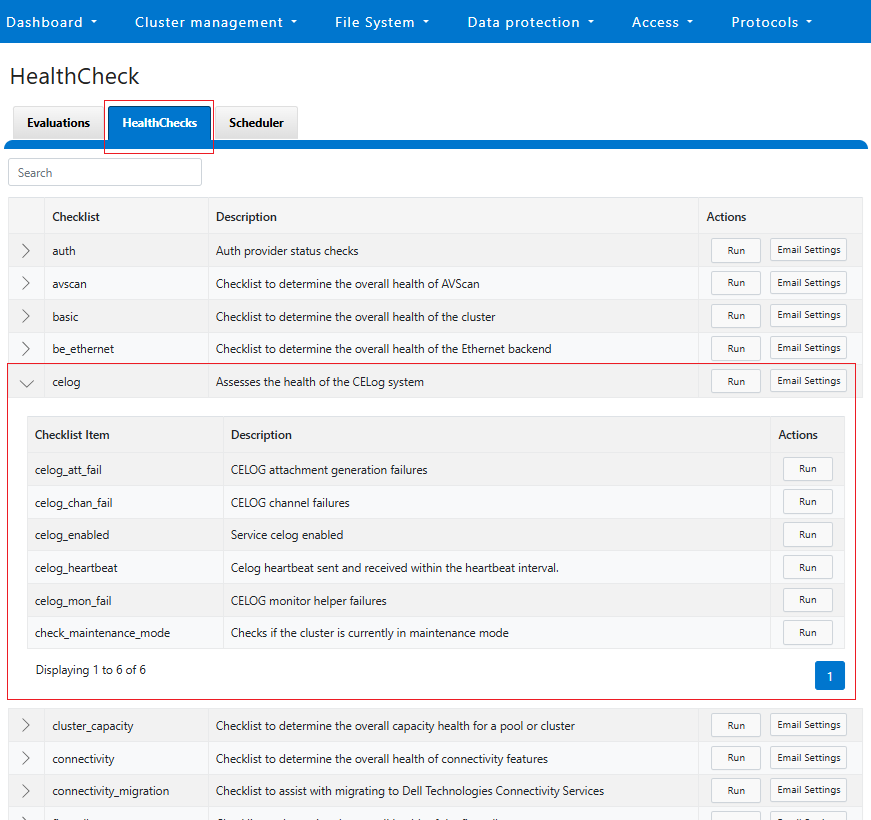
DTCS can be configured from the OneFS 9.10 WebUI by navigating to ‘Cluster management > General settings > DTCS’.
When unconfigured, the Connectivity Services WebUI page also displays verbiage recommending the adoption of DTCS:
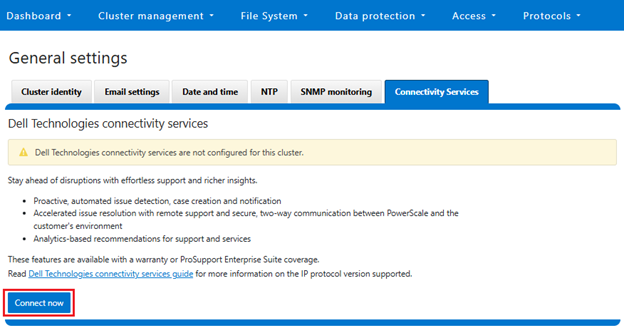
- Accepting the telemetry notice.

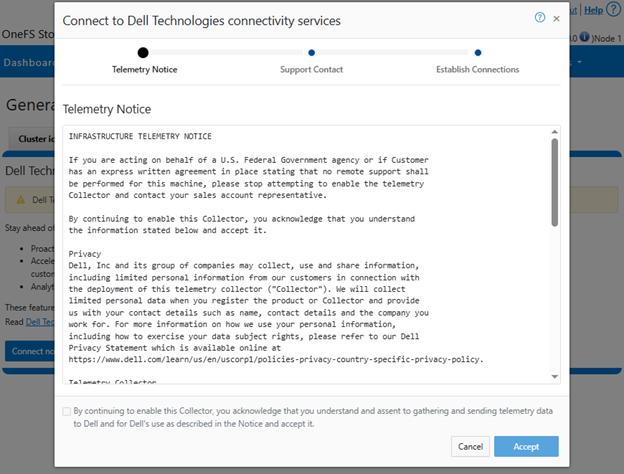
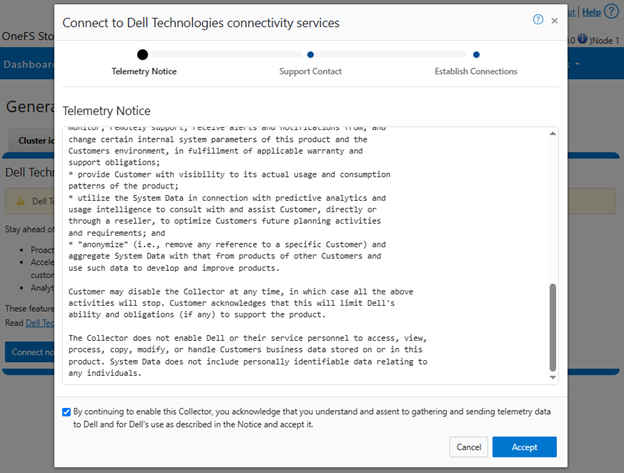
Selecting the ‘Connect Now’ button initiates the following setup wizard. The first step requires checking and accepting the Infrastructure Telemetry Notice:
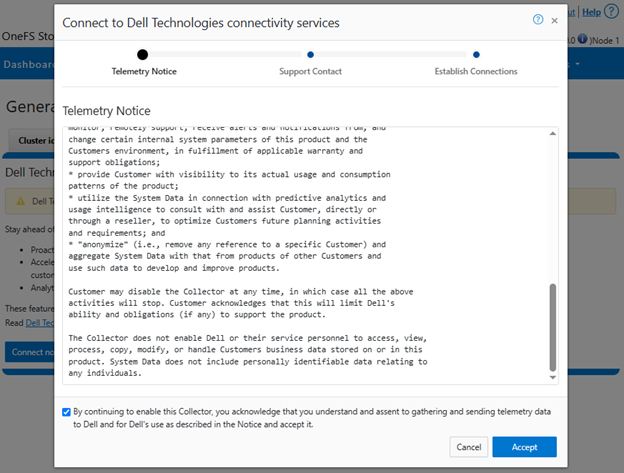
- Support Contract.

For the next step, enter the details for the primary support contact, as prompted:
Or from the CLI using the ‘isi connectivity contacts’ command set. For example:
# isi connectivity contacts modify --primary-first-name=Nick --primary-last-name=Trimbee --primary-email=trimbn@isilon.com
- Establish Connections.

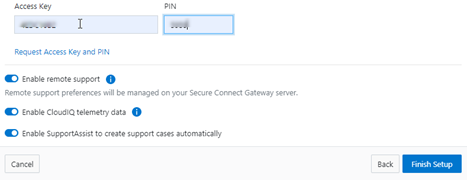
Next, complete the ‘Establish Connections’ page
This involves the following steps:

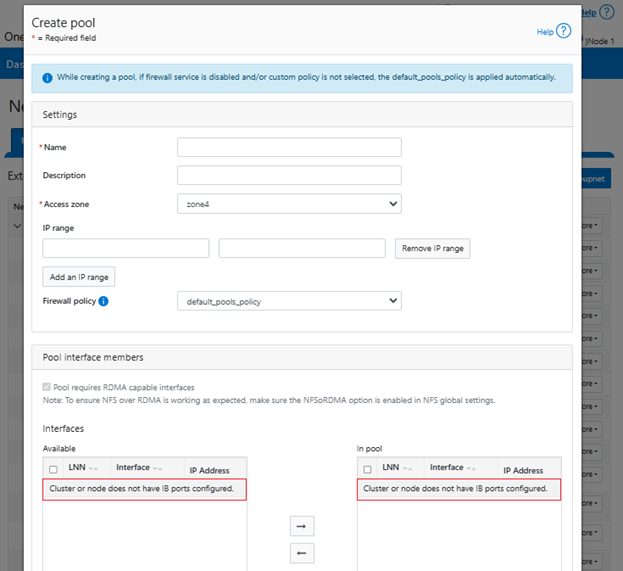
- Selecting the network pool(s).
- Adding the secure access key and PIN,
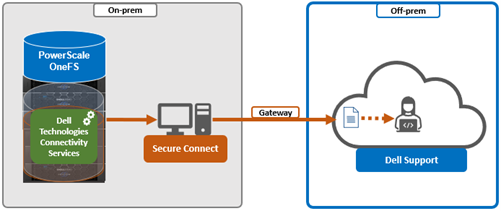
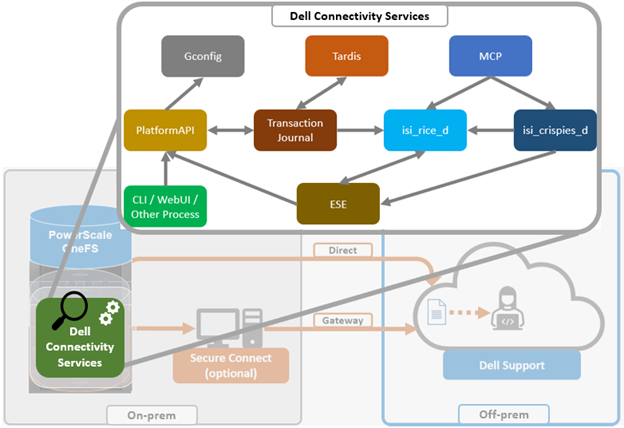
- Configuring either direct or gateway access
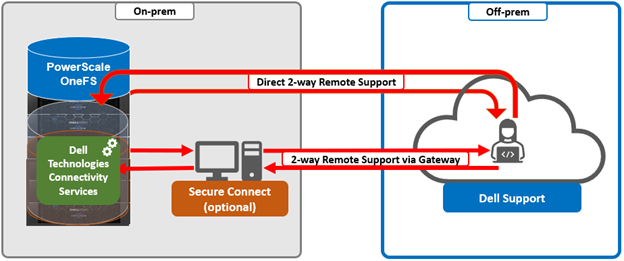
- Selecting whether to allow remote support, CloudIQ telemetry, and auto case creation.
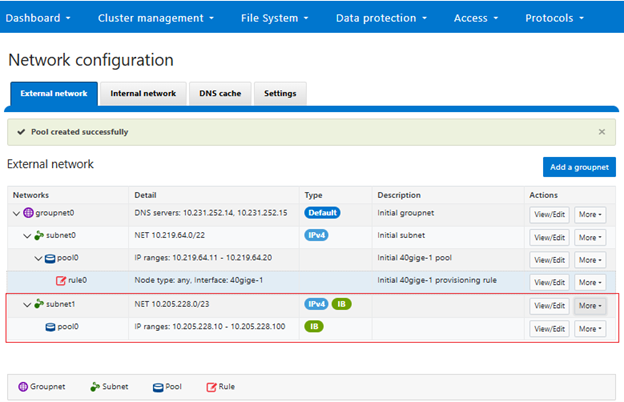
a. Select network pool(s).

At least one statically-allocated IPv4 or IPv6 network subnet and pool is required for provisioning DTCS.
Select one or more network pools or subnets from the options displayed. For example, in this case ‘subnet0pool0’:
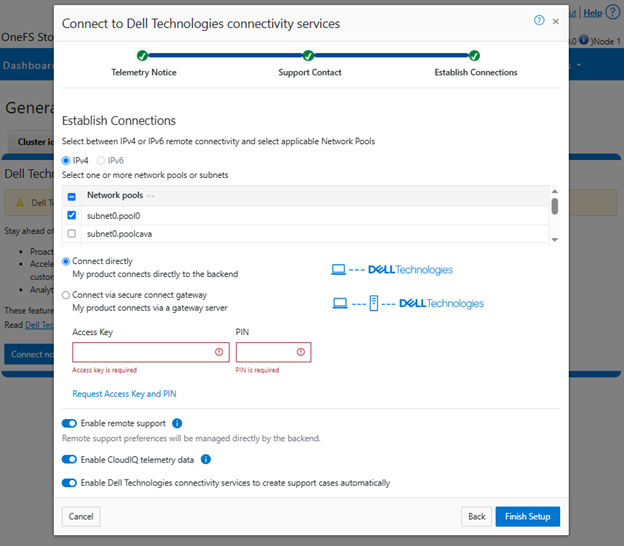
Or from the CLI:
Select one or more static subnet/pools for outbound communication. This can be performed via the following CLI syntax:
# isi connectivity settings modify --network-pools="subnet0.pool0"
Additionally, if the cluster has the OneFS network firewall enabled (‘isi network firewall settings’), ensure that outbound traffic is allowed on port 9443.
b. Add secure access key and PIN.

In this next step, add the secure access key and pin. These should have been obtained in an earlier step in the provisioning procedure from the following Dell Support site: https://www.dell.com/support/connectivity/product/isilon-onefs.:
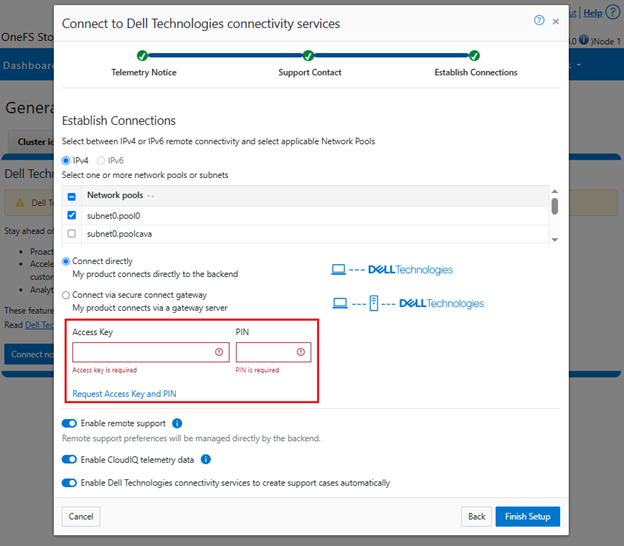
Alternatively, if configuring DTCS via the OneFS CLI, add the key and pin via the following syntax:
# isi connectivity provision start --access-key <key> --pin <pin>
c. Configure access.
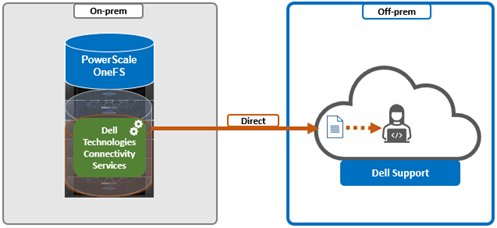
i. Direct access.

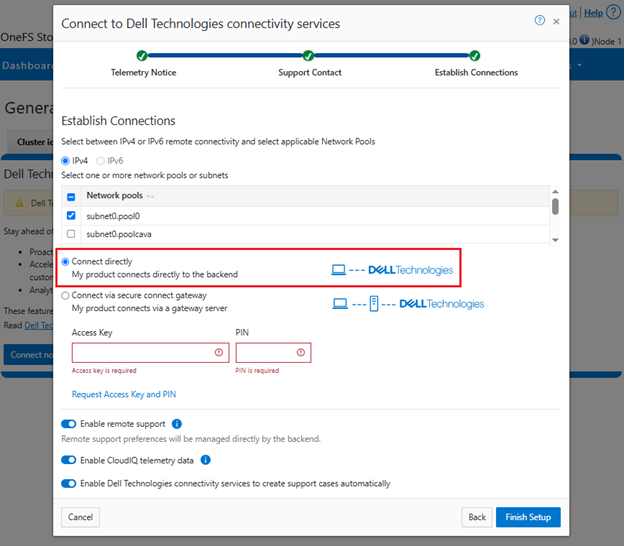
Or from the CLI. For example, to configure direct access (the default), ensure the following parameter is set:
# isi connectivity settings modify --connection-mode direct # isi connectivity settings view | grep -i "connection mode" Connection mode: direct
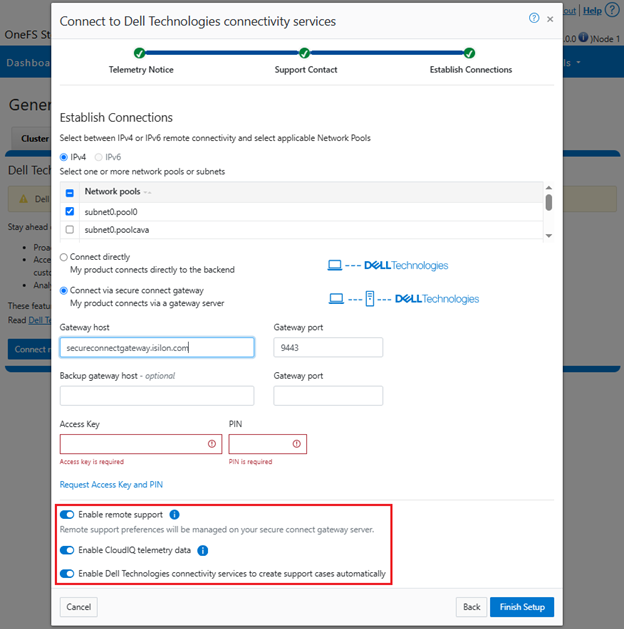
ii. Gateway access.

Alternatively, to connect via a gateway, check the ‘Connect via Secure Connect Gateway’ button:

Complete the ‘gateway host’ and ‘gateway port’ fields as appropriate for the environment.
Alternatively, to set up a gateway configuration from the CLI, use the ‘isi connectivity settings modify’ syntax. For example, to configure using the gateway FQDN ‘secure-connect-gateway.yourdomain.com’ and the default port ‘9443’:
# isi connectivity settings modify --connection-mode gateway # isi connectivity settings view | grep -i "connection mode" Connection mode: gateway # isi connectivity settings modify --gateway-host secure-connect-gateway.yourdomain.com --gateway-port 9443
When setting up the gateway connectivity option, Secure Connect Gateway v5.0 or later must be deployed within the data center. Note that DTCS is incompatible with either ESRS gateway v3.52 or SAE gateway v4. However, Secure Connect Gateway v5.x is backwards compatible with PowerScale OneFS ESRS and SupportAssist, which allows the gateway to be provisioned and configured ahead of a cluster upgrade to DTCS/OneFS 9.10.
d. Configure support options.

Finally, configure the desired support options:
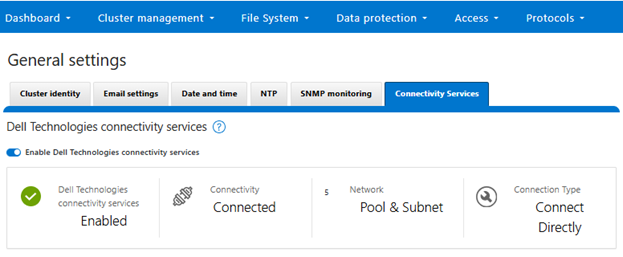
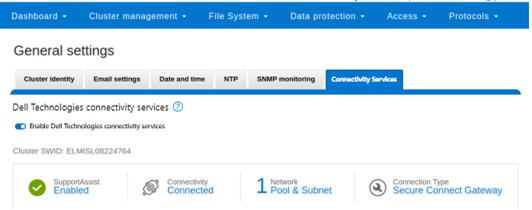
When complete, the WebUI will confirm that SmartConnect is successfully configured and enabled, as follows:
Or from the CLI:
# isi connectivity settings view Service enabled: Yes Connection State: enabled OneFS Software ID: ELMISL0223BJJC Network Pools: subnet0.pool0, subnet0.testpool1, subnet0.testpool2, subnet0.testpool3, subnet0.testpool4 Connection mode: gateway Gateway host: eng-sea-scgv5stg3.west.isilon.com Gateway port: 9443 Backup Gateway host: eng-sea-scgv5stg.west.isilon.com Backup Gateway port: 9443 Enable Remote Support: Yes Automatic Case Creation: Yes Download enabled: Yes
Having worked through getting DTCS configured, up and running, in the next article in this series we’ll turn our attention to the management and troubleshooting of DTCS.








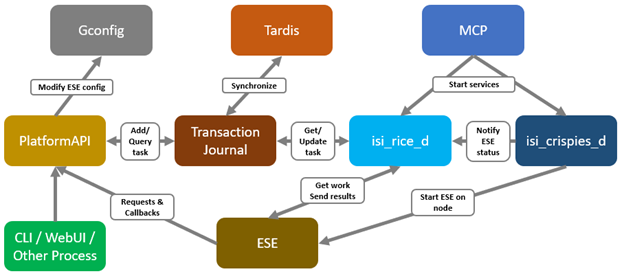






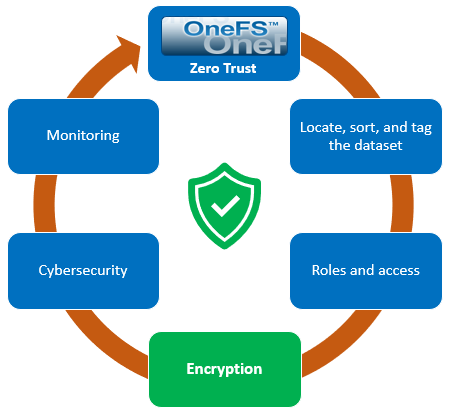
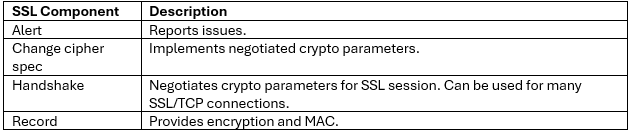
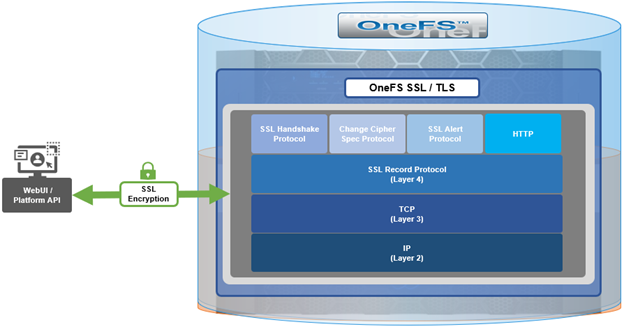
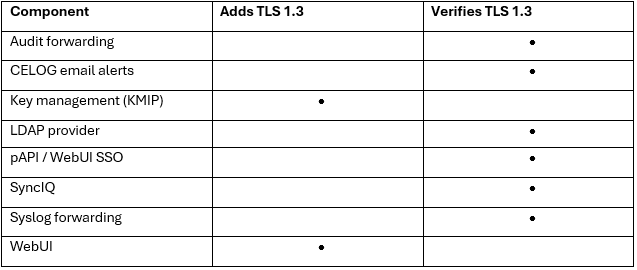
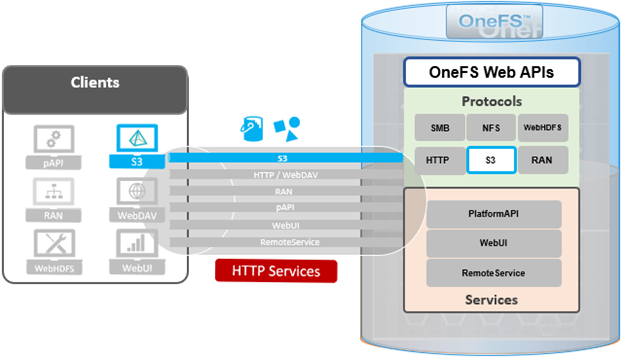
 When using either the OneFS WebUI or platform API (pAPI), all communication sessions are encrypted using SSL and the related Transport Layer Security (TLS). As such, SSL and TLS play a critical role in PowerScale’s Zero Trust architecture by enhancing security via encryption, validation, and digital signing.
When using either the OneFS WebUI or platform API (pAPI), all communication sessions are encrypted using SSL and the related Transport Layer Security (TLS). As such, SSL and TLS play a critical role in PowerScale’s Zero Trust architecture by enhancing security via encryption, validation, and digital signing.