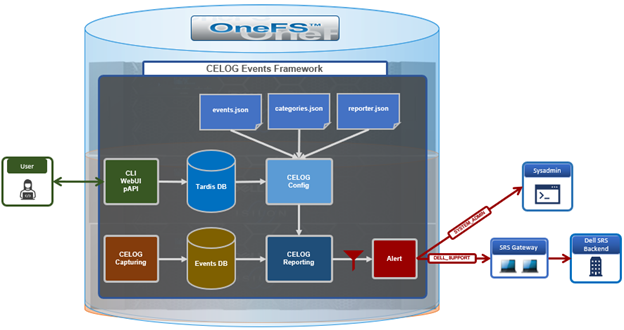
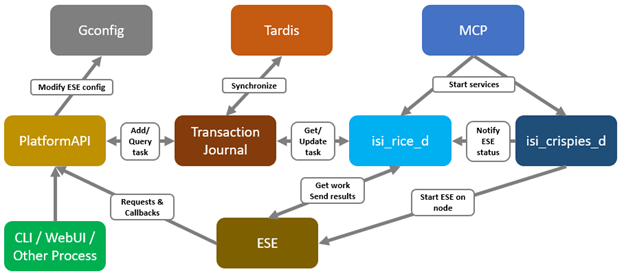
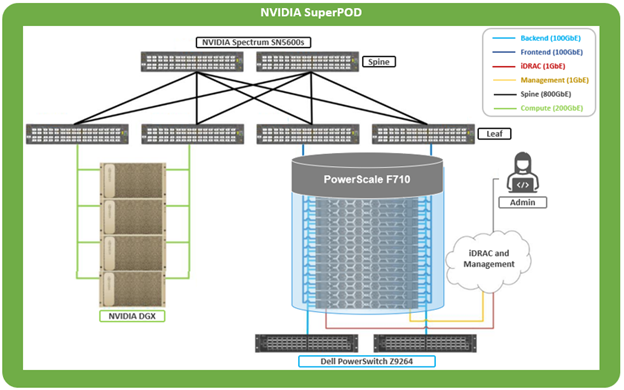
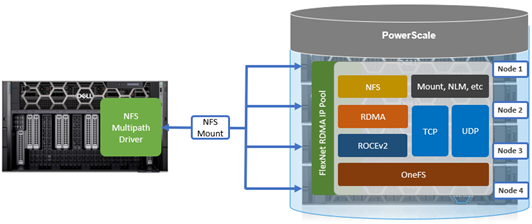
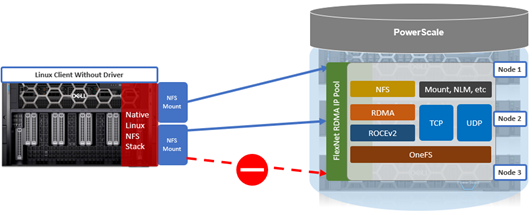
Another piece of functionality that OneFS 9.9 brings to the table is automatic maintenance mode (AMM). AMM builds upon and extends the manual CELOG maintenance mode capability, which has been an integral part of OneFS since the 9.2 release.
Cluster maintenance operations such as upgrades, patch installation, rolling reboots, hardware replacement, etc, typically generate a significant increase in cluster events and alerts. This can be overwhelming for the cluster admin, who’s trying to focus on the maintenance task at hand and, as such, well aware of the issue. So, as the name suggests, the general notion of OneFS maintenance mode is to provide a method of temporarily suspending these cluster notifications.
So during a maintenance window with maintenance mode enabled, OneFS will continue to log events but not generate alerts for them. As such, all events that occurred during the maintenance window can then be reviewed upon manually disabling maintenance mode. Active event groups will automatically resume generating alerts when the scheduled maintenance period ends.
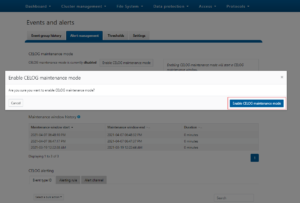
Until OneFS 9.9, activating maintenance mode has been a strictly manual process. For example, to enable CELOG maintenance mode from the OneFS WebUI select Cluster Management > Events and Alerts and click on the ‘Enable maintenance mode’ button:
Alas, as with most manually initiated and terminated processes, they’re only as reliable as the operator. As such, purely manual operation runs the risk of missed critical alerts if maintenance mode is not disabled after a maintenance window has concluded.
In contrast, the new OneFS 9.9 AMM functionality automatically places clusters or nodes in maintenance mode based on predefined triggers, such as the following:
| AMM Trigger | Description | Action |
| Simultaneous upgrade | OneFS full cluster upgrade and all nodes simultaneous reboot. | Cluster enters maintenance mode at upgrade start and exits maintenance mode when the last node finishes upgrade. |
| Upgrade rollback | Reverting a OneFS upgrade to the previous version prior to upgrade commit. | Cluster enters maintenance mode at rollback start, and exits maintenance mode when the last node finishes its downgrade. |
| Node Reboot | Rebooting a PowerScale node. | Node is added to maintenance mode as reboot starts, and exits maintenance mode when reboot completes. |
| Node addition/removal | Joining or removing a node to/from a PowerScale cluster. | Node is added to maintenance mode as join/removal starts, and exits maintenance mode when join/removal is completed. |
During maintenance mode, CELOG alerts are suppressed, ensuring that the cluster or node can undergo necessary updates or modifications without generating a flurry of notifications. This feature is particularly useful for organizations that need to perform regular maintenance tasks but want to minimize disruptions to their workflows (and keep their cluster admins sane).
When a maintenance window is triggered, such as for a rolling upgrade, the entire cluster enters maintenance mode at the start and exits when the last piece of the upgrade operation has completed. Similarly, when a node is rebooted, it is added to maintenance mode at the start of the reboot and removed when the rebooting finishes.
Automatic maintenance mode windows have a maximum time limit of 199 hours. This is in order to prevent an indefinite maintenance mode conditions and avoid the cluster being left in limbo, any associated issues. Plus, the cluster admin can easily manually override AMM and end the maintenance window at any time.
OneFS AMM offers a range of configuration options, including the ability to control automatic activation of maintenance mode, set manual maintenance mode durations, and specify start times. AMM also keeps a detailed history of all maintenance mode events, providing valuable insights for troubleshooting and system optimization.
Under the hood, there’s a new gconfig tree in OneFS 9.9 named ‘maintenance’, which holds the configuration for both automatica and manual maintenance mode:
| Attribute | Description |
| active | Indicates if maintenance mode is active |
| auto_enable | Controls automatic activation of maintenance mode |
| manual_window_enabled | Indicates if a manual maintenance mode is active |
| manual_window_hours | The number of hours a manual maintenance window will be active |
| manual_window_start | The start time of the current manual maintenance window |
| maintenance_nodes | List of node LNNs in maintenance mode (0 indicates cluster wide) |
For example:
# isi_gconfig -t maintenance
[root] {version:1}
maintenance.auto_enable (bool) = true
maintenance.active (bool) = false
maintenance.manual_window_enabled (bool) = false
maintenance.manual_window_hours (int) = 8
maintenance.manual_window_start (int) = 1732062847
maintenance.maintenance_nodes (char*) = []
These attributes are also reported by the ‘isi cluster maintenance status’ CLI command. For example:
# isi cluster maintenance status Auto Maintenance Mode Enabled: Yes Maintenance Mode Active: No Manual Maintenance Window Enabled: No Manual Maintenance Window Duration: 8 Hours Manual Maintenance Window Start Time: - Manual Maintenance Window End Time: -
There’s also a new OneFS Tardis configuration tree, also named ‘maintenance’, which includes both a list of the components supported by maintenance mode and their status, and a historical list of all the maintenance mode events and their timestamps on a cluster.
| Branch | Attribute | Description |
| Components | List of components supported by maintenance mode. | |
| Active | Active – indicates if this component is currently in maintenance mode. | |
| Enabled | Enabled – indicates if this component can go into maintenance mode. | |
| Name | Name – is the name of the component this settings block controls. | |
| History | List of all maintenance mode events on the cluster. | |
| Start | Start – timestamp for when this maintenance event started. | |
| End | Timestamp for when this maintenance event ended. | |
| Mode | Either ‘auto’ or ‘manual’, indicating how maintenance event was started. |
These attributes and their values can be queried by the ‘isi cluster maintenance components view’ and isi cluster maintenance history view’ CLI commands respectively. For example:
# isi cluster maintenance components view Name Enabled Active --------------------------------- Event Alerting Yes Yes
Also:
# isi cluster maintenance history view Mode Start Time End Time ---------------------------------------------------------- auto Sun Nov 3 15:12:45 2024 Sun Nov 3 18:41:05 2024 manual Tue Nov 19 19:43:14 2024 Tue Nov 19 19:43:43 2024 manual Wed Nov 20 00:05:22 2024 Wed Nov 20 00:05:48 2024
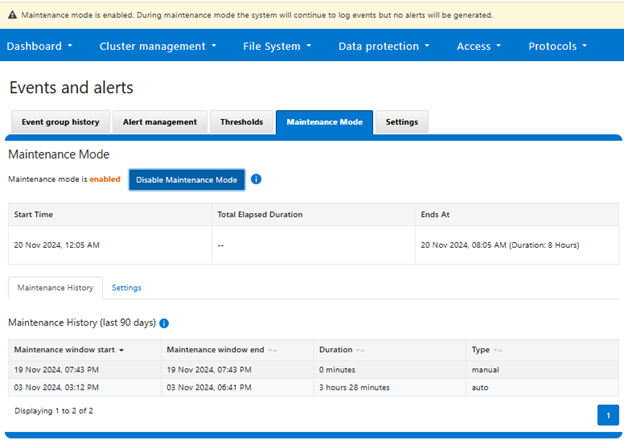
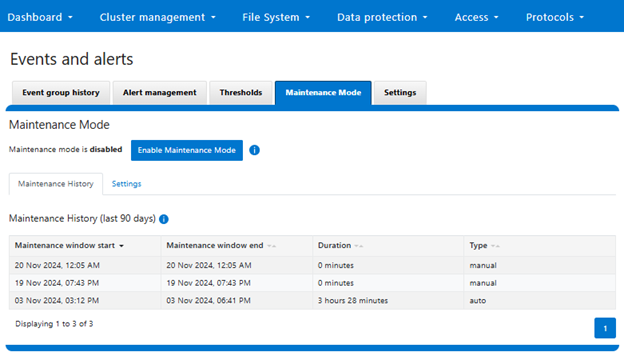
Similarly, the maintenance mode’s prior 90 day history from the WebUI:
If the legacy ‘isi event maintenance’ CLI syntax is invoked, a gentle reminder to use the new ‘isi cluster maintenance’ command set is returned:
# isi event maintenance 'isi cluster maintenance' is now used to manage maintenance mode windows.
AMM can be easily enabled from the OneFS 9.9 CLI as follows:
# isi cluster maintenance settings modify --auto-enable true # isi cluster maintenance settings view | grep -i auto Auto Maintenance Mode Enabled: Yes
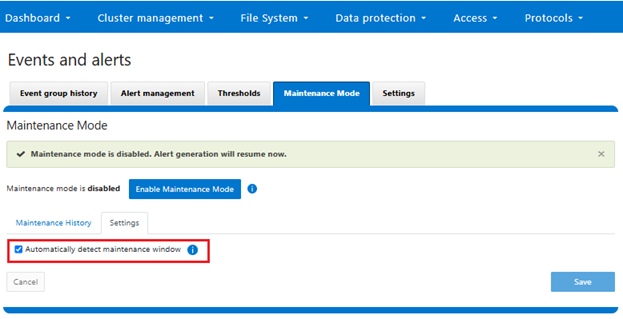
Similarly from the WebUI, under Cluster management > Events and alerts > Maintenance mode:
When accessing a cluster with maintenance mode activated, the following warning will be broadcast:
Maintenance mode is active. Check 'isi cluster maintenance status' for more details.
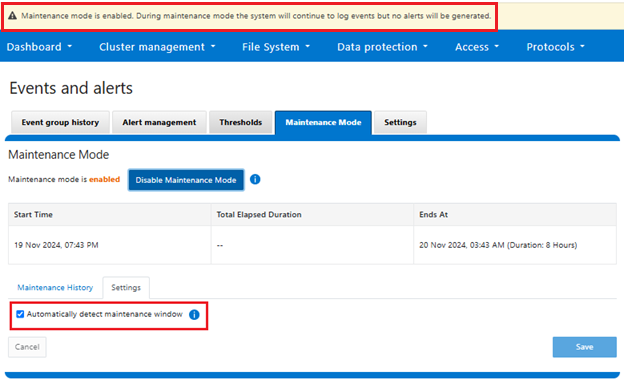
Similarly from the WebUI:
So once AMM has been enabled on a cluster, how do things look when a triggering event occurs? For simultaneous upgrade, the following sequence occurs:
Initially, AMM is reported as being enabled, but maintenance mode is inactive:
# isi cluster maintenance Auto Maintenance Mode Enabled: Yes Maintenance Mode Active: No Manual Maintenance Window Enabled: No Manual Maintenance Window Duration: 8 Hours Manual Maintenance Window Start Time: - Manual Maintenance Window End Time: -
Next, a simultaneous upgrade is initiated:
# isi upgrade cluster start --simultaneous /ifs/data/install.isi
You are about to start a simultaneous UPGRADE. Are you sure? {yes/[no]}: yes
Verifying the specified package and parameters.
The upgrade has been successfully initiated.
‘isi upgrade view [--interactive | -i]’ or the web ui can be used to monitor the process.
A maintenance mode window is automatically started and reported as active:
# isi cluster maintenance Auto Maintenance Mode Enabled: Yes Maintenance Mode Active: Yes Manual Maintenance Window Enabled: No Manual Maintenance Window Duration: 8 Hours Manual Maintenance Window Start Time: - Manual Maintenance Window End Time: -
During a simultaneous upgrade, the gconfig ‘maintenance_nodes’ parameter will report a cluster-wide event (value =0, which indicates all nodes):
# isi_gconfig -t maintenance | grep -i node maintenance.maintenance_nodes (char*) = [0]
Once the upgrade has completed and is ready to commit, the maintenance mode window is no longer active:
# isi upgrade view Upgrade Status: Current Upgrade Activity: OneFS upgraded Cluster Upgrade State: Ready to commit Upgrade Process State: Running Upgrade Start Time: 2024-11-21T15:12:20.803000 Current OS Version: 9.9.0.0_build(4)style(5) # isi cluster maintenance Auto Maintenance Mode Enabled: Yes Maintenance Mode Active: No Manual Maintenance Window Enabled: No Manual Maintenance Window Duration: 8 Hours Manual Maintenance Window Start Time: - Manual Maintenance Window End Time: -
Finally, the maintenance history shows the duration of the AMM window:
# isi cluster maintenance history view Mode Start Time End Time ---------------------------------------------------------- auto Sun Nov 21 15:12:45 2024 Sun Nov 3 18:41:05 2024
Similarly, for a node reboot scenario. Once the reboot command has been run on a node, the cluster automatically activates a maintenance mode window:
# reboot System going down IMMEDIATELY … # isi cluster maintenance Auto Maintenance Mode Enabled: Yes Maintenance Mode Active: Yes Manual Maintenance Window Enabled: No Manual Maintenance Window Duration: 8 Hours Manual Maintenance Window Start Time: - Manual Maintenance Window End Time: -
A this point, the gconfig ‘maintenance_nodes’ parameter will report the logical node number (LNN) of the rebooting node:
# isi_gconfig -t maintenance | grep -i node maintenance.maintenance_nodes (char*) = [3]
In this example, the rebooting node has both LNN 3 and node ID 3 (although matching LNN and IDs are not always the case):
# isi_nodes %{id} , %{lnn}~ | grep "3 ,"
3 , 3~
Finally, the maintenance window is reported inactive when the node is back up and running again:
# isi cluster maintenance Auto Maintenance Mode Enabled: Yes Maintenance Mode Active: No Manual Maintenance Window Enabled: No Manual Maintenance Window Duration: 8 Hours Manual Maintenance Window Start Time: - Manual Maintenance Window End Time: -
When upgrading from OneFS versions prior to 9.9, if a maintenance mode window was manually enabled prior to the upgrade, it will continue to be active after the upgrade. The maintenance window is manual, and the maintenance window hours are set to 199 during the upgrade, then restored to the default of 8 on commit. Maintenance mode history is also migrated during the upgrade process. If necessary, an upgrade rollback restores ‘isi event maintenance’.
In the event of any issues during maintenance mode operations, error conditions and details are written to the /var/log/isi_maintenance_mode_d.log file. This file can be set to debug level logging for more verbose information. Additionally, the /var/log/isi_shutdown.log and isi_upgrade_logs files can often provide further insights and context.
| Logfile | Description |
| /var/log/isi_maintenance_mode_d.log | • Will show errors that occur during maintenance mode operations
• Can be set to debug level logging for more details |
| /var/log/isi_shutdown.log | Cluster and node shutdown log |
| isi_upgrade_logs | Cluster upgrade logs |