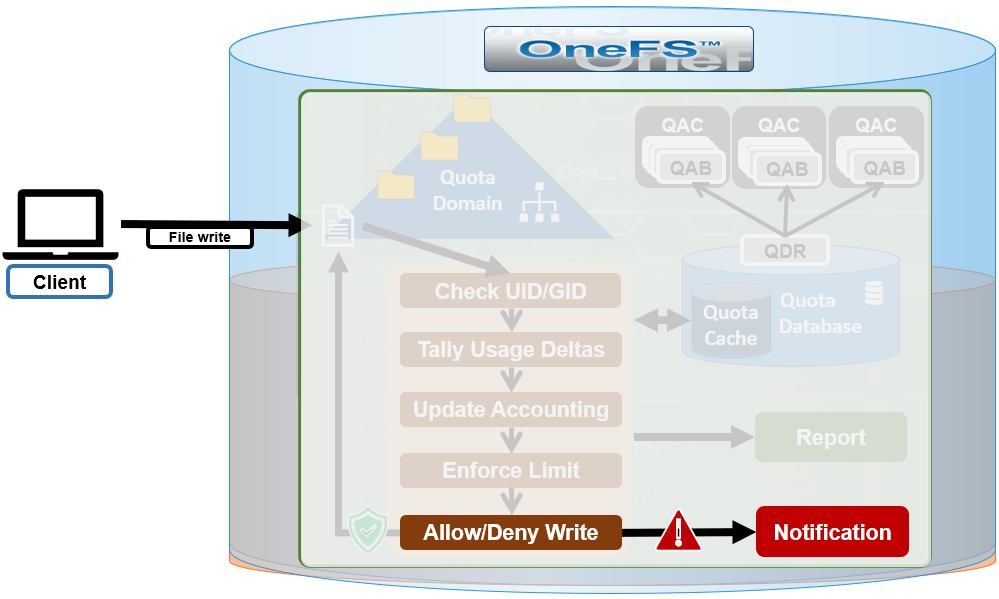
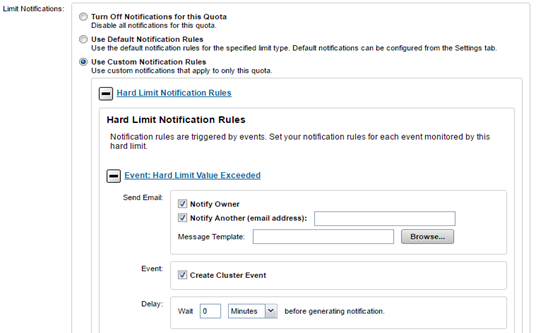
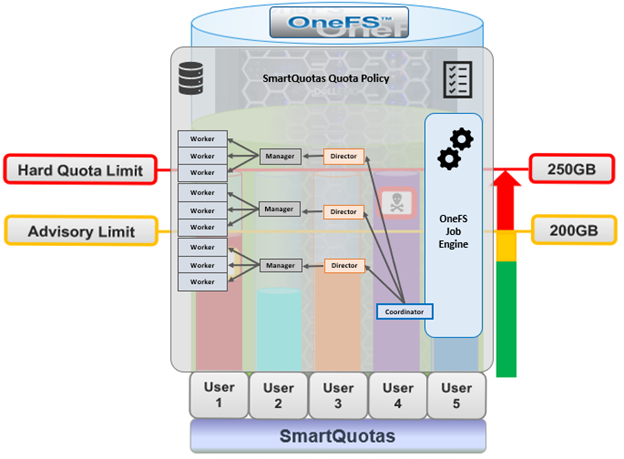
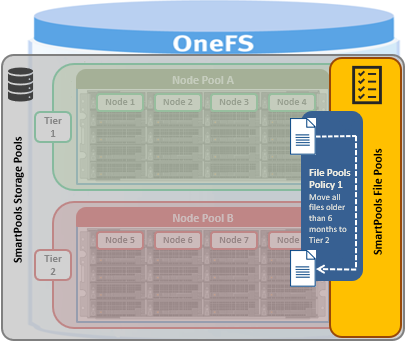
In this next article in the OneFS SmartQuotas series we turn our attention to quota accounting and reporting:
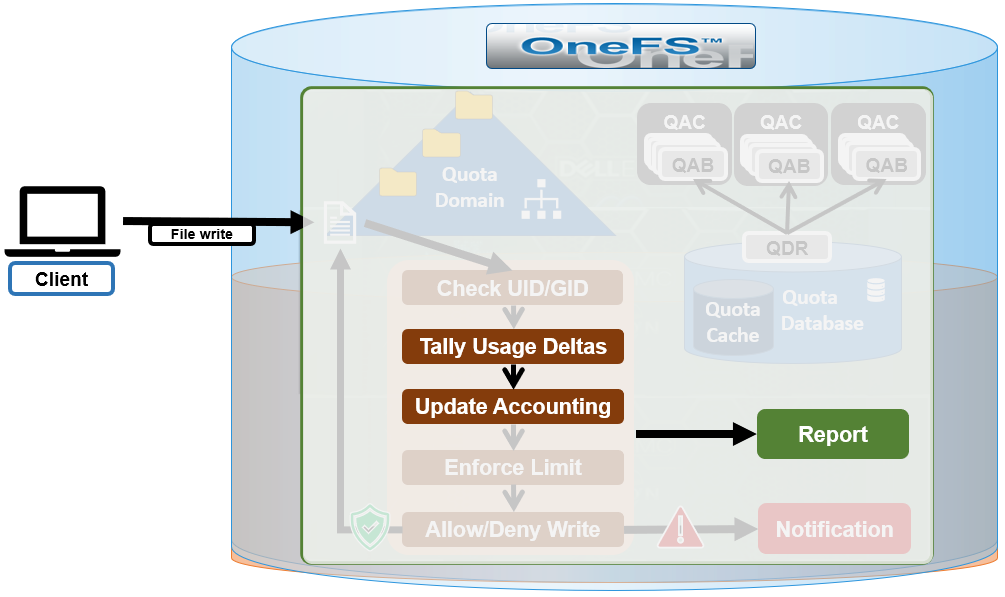
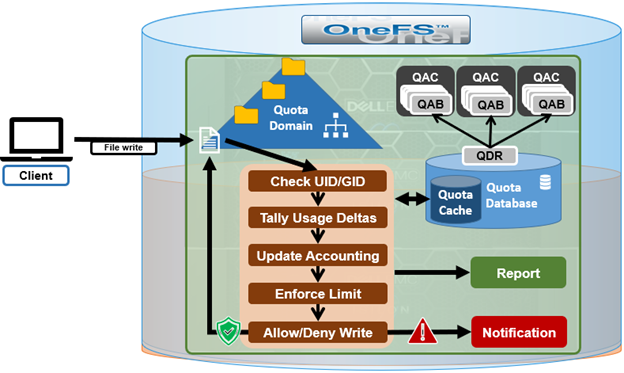
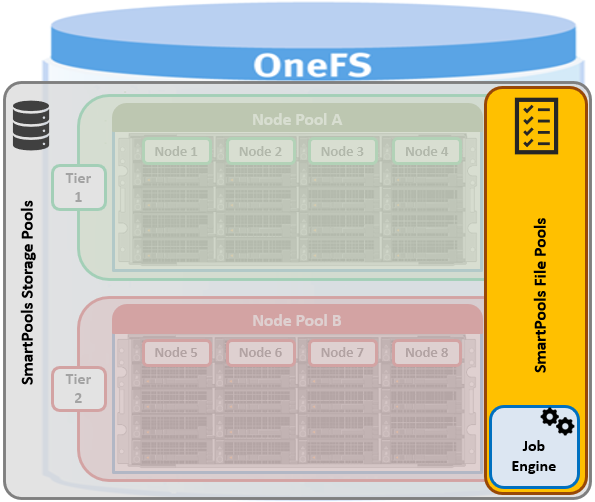
SmartQuotas has four main resources used in quota accounting:
| Accounting Resource | Description |
| Physical Size | This includes all the on-disk storage associated with files and directories, with the exception of some metadata objects including the LIN tree, snapshot tracking files (STFs). For deduplicated data and file clones, each file’s 8 KB reference to a shadow store is included in the physical space calculation. |
| File system logical size | File system logical size calculation approximates disk usage on ‘typical’ storage arrays by ignoring the erasure code, or FEC, protection overhead that OneFS employs. For regular files, the logical data space is the amount of storage required to house a particular file if it was 1x mirrored. Logical space also incorporates a file’s metadata resources. |
| Application Logical Size | Reports total logical data store across different tiers, including CloudPools. This allows users to view quotas and free space as an application would view it, in terms of how much capacity is available to store logical data regardless of data reduction or tiering technology. |
| Inodes | SmartQuotas counts the number of logical inodes, which allows accounting for files without any ambiguity from hard links or protection. |
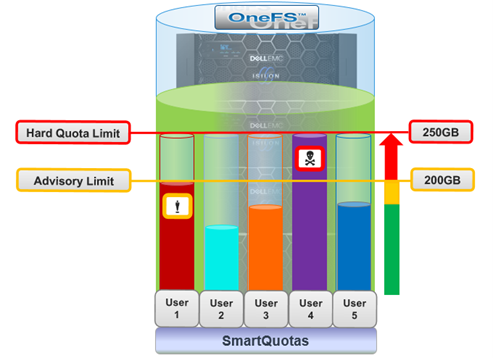
When configuring a quota, these are accounting resource options are available as enforcement limits. For example, from the OneFS WebUI:
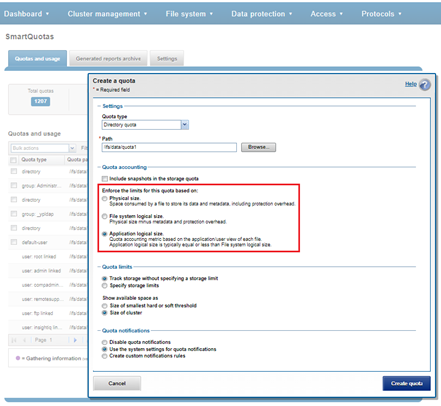
Application logical size quotas are available in OneFS 8.2 and later. Existing quotas can easily be configured to use application logical size upon upgrading from an earlier OneFS version. The benefits of application logical size quotas include:
- Snapshots, protection overhead, deduplication, compression, and location of files all have no effect on quota consumption
- Removes previous limitation where SmartQuotas only reported on-cluster storage, ignoring cloud consumption
- Presents view that aligns with Windows storage accounting
- Enables accounting and enforcing quota on actual file sizes
- Precisely accounts for small files
- Enables enforcing quotas on a path irrespective of the physical location of file.
The following table describes how SmartQuotas accounts for a 1KB file with the various datatypes:
| Data Type | Accounting |
| File: physical size | Every non-sparse 8 KB disk block a file consumes including protection |
| File: file system logical size | Every non-sparse 8 KB disk block a file consumes excluding protection |
| File: application logical size | Actual size of file (rather than total of 8 KB disk blocks consumed) |
| CloudPools file: file system logical size | Size of CloudPools SmartLink stub file (8 KB) |
| CloudPools file: application logical size | Actual size of file on cloud storage (rather than local stub file) |
| Directories | Sum of all directory entries |
| Symlinks | Data size |
| ACL and similar | Data size |
| Alternate data stream | Each ADS is charged as a file and a container as a directory |
The example below shows each method of accounting for a 1KB file.
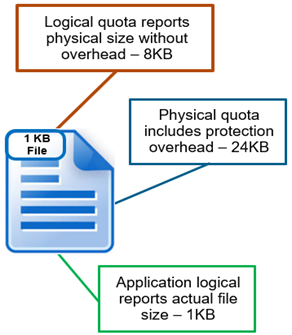
| Method | Details |
| Logical size accounting | Sum of physical sizes of all files/directories without overhead. |
| Physical size accounting | Sum of physical sizes of all files/dirs with protection overhead. |
| Application Logical Accounting | Sum of actual sizes of all files/directories. |
So the logical size is reported as 8 KB, or one block, physical size reports 24 KB (file with 3x mirroring protection), and application logical shows its actual size of 1 KB.
Other resources encountered during quota accounting include:
| Resource | Description |
| Hard Link | Each logical inode is accounted exactly once in every domain to which it belongs. If an inode is present in multiple domains, it is accounted in multiple domains. Alternatives such as shared accounting were considered. However, if inodes are not accounted once in every domain, it is possible for the deletion of a hard link in one domain to put another domain over quota. |
| Alternate Data Stream (ADS) | A file with an alternate data stream or resource fork is accounted as the sum of the resource usage of the individual file, the usage for the container directory and the usage for each ADS. SmartQuotas handles the rename of a file with ADS synchronously, despite the fact that the ADS container is just a directory. SmartQuotas will store an accounting summary on the ADS container to handle renames. |
| Directory Rename | A directory rename presents a unique challenge to a per-directory quota system. Renames of directories within a domain are trivial – if both the source and target directories have the same domain membership, no accounting changes. However, non-empty directories are not permitted to be moved when the SmartQuotas configuration is different on the source and the target parent directories. If a user trusts the client operating systems to copy files and preserve all the necessary attributes, then the user may set dir_rename_errno to EXDEV, which causes most UNIX and Windows clients to do a copy and delete of the directory tree to affect the move. |
| Snapshot Accounting | If wanted, a quota domain can also include snapshot usage in its accounting. SmartQuotas will only support snapshots created after the quota domain was created. This is because determining quota governance (including QuotaScan job) for existing snapshots is a very time and resource consuming operation. As most administrators cycle their snapshots through timed expirations, SmartQuotas will eventually accrue enough accounting information to include the entire set of relevant snapshots on the system. |
SmartQuotas supports flexible reporting options that enable administrators to more effectively manage cluster resources and analyze usage statistics. The goal of Quota Reporting is to provide a summarized view of the past or present state of the Quota Domains. There are three methods of data collection and reporting that are supported:
| Reporting Method | Detail |
| Scheduled | Scheduled reports are generated and saved on a regular interval. |
| Ad-hoc | Ad-hoc reports are generated and saved per request of the user. |
| Live | Live reports are generated for immediate and temporary viewing |
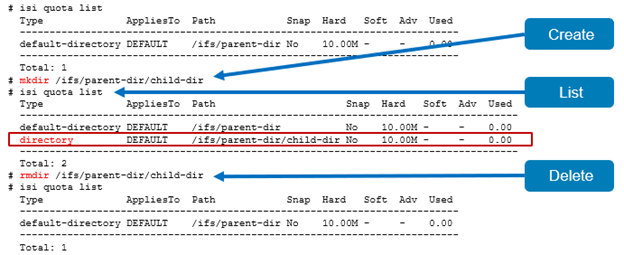
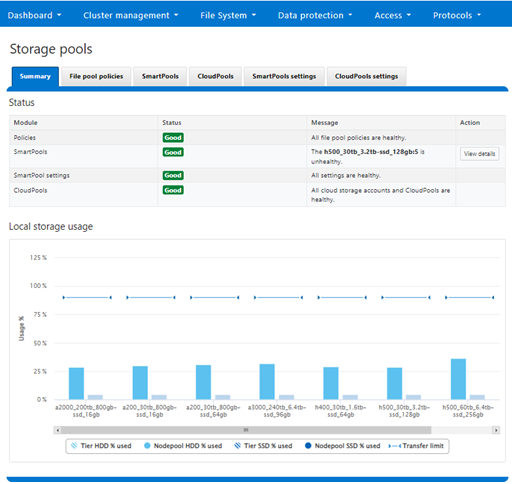
A summary of general quota usage info can be viewed from the CLI via the ‘isi quota quotas list’ command syntax. Or from the WebUI, by navigating to File System > SmartQuotas > Quotas and Usage.
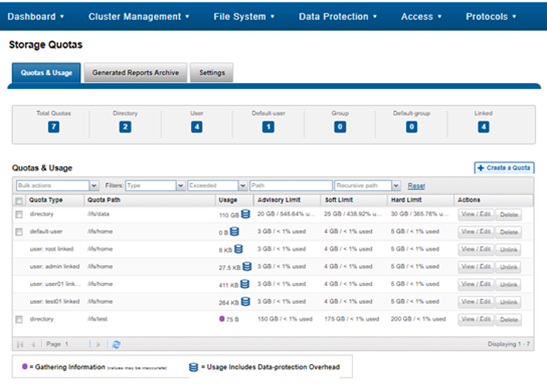
For each quota entry, additional information and context is available via the ‘isi quota quotas view <quota_name>’ CLI command, or by clicking on the WebUI ‘View / Edit’ button:
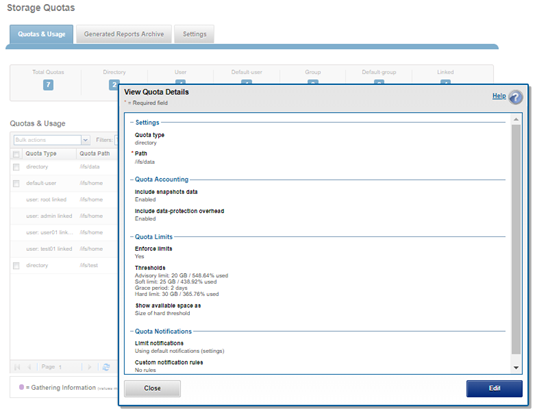
Client-side quota reporting includes support for rpc.quotad, which allows NFS clients to view quota consumption for both hard and soft quotas using the native Linux and UNIX ‘quota’ CLI utilities. There is also the ability to view available user capacity set by soft and/or hard user or group quotas, rather than the entire cluster capacity or parent directory-quotas.
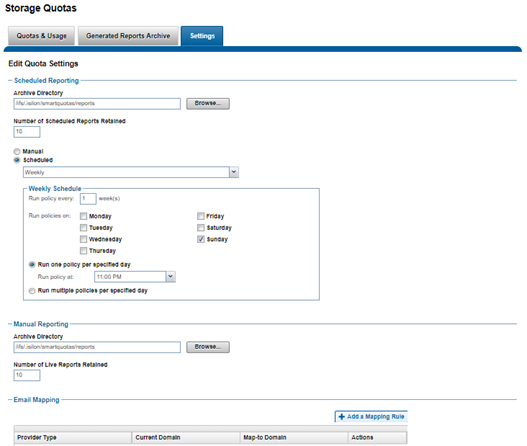
The quota reports and summaries are typically stored in the /ifs/.isilon/smartquotas/reports directory, but this location is configurable. Each generated report includes the quota domain definition, state, usage, and global configuration settings. By default, ten reports and ten summaries are kept at a time, and older versions are purged. This can be configured from the WebUI, by navigating to File System > SmartQuotas > Settings:
On demand reports can also be created at any time to view the current state of the storage quotas system. These live reports can be saved manually.
Reports and summaries are prefixed by either ‘ad hoc’ or ‘scheduled’ to aid with identification.
The OneFS CLI export functionality makes use of the same data generation and storage format as quota reporting but should not require any extra requirements beyond the three types of reports. After the collection of the raw reporting data, data summaries can be produced given a set of filtering parameters and sorting type.
Reports can be viewed from historical sampled data or a live system. In either case, the reports are views of usage data at a given time. SmartQuotas does not provide reports on aggregated data over time (trending reports). However, the raw data can be used by a Quota Administrator to answer trending questions.
A quota report is a time-stamped XML file that starts off with global configuration settings and global notification rules:
# cat scheduled_quota_report_1465786800.xml <global-config> <quota-global-config> <reports> <schedule-pattern>1100000000|every sunday at 11pm</schedule-pattern> <schedule-dir>/ifs/.isilon/smartquotas/reports</schedule-dir> <schedule-copies>10</schedule-copies> <adhoc-dir>/ifs/.isilon/smartquotas/reports</adhoc-dir> <adhoc-copies>10</adhoc-copies> </reports> </quota-global-config> </global-config> <global-notify> </global-notify> <domains> <domain type="default-group" snaps="0" lin="0x0000000100020006"> <path>/ifs/home</path> <inactive/> <enforcements default-resource="logical"> </enforcements> <notifications use="global"/> </domain> <domain type="group" snaps="0" lin="0x0000000100020006" id="0"> <inherited/> <id-name>wheel</id-name> <usage resource="physical">109568</usage> <usage resource="logical">32929</usage> <usage resource="inodes">6</usage> <path>/ifs/home</path> <inactive/> <enforcements default-resource="logical"> </enforcements> <notifications use="default"/> </domain> <domain type="group" snaps="0" lin="0x0000000100020006" id="10"> <inherited/> <id-name>admin</id-name> <usage resource="physical">28160</usage> <usage resource="logical">8208</usage> <usage resource="inodes">2</usage> <path>/ifs/home</path> <inactive/> <enforcements default-resource="logical"> </enforcements> <notifications use="default"/> </domain> <domain type="group" snaps="0" lin="0x0000000100020006" id="1800"> <inherited/> <id-name>Isilon Users</id-name> <usage resource="physical">1811456</usage> <usage resource="logical">705620</usage> <usage resource="inodes">42</usage> <path>/ifs/home</path> <inactive/> <enforcements default-resource="logical"> </enforcements> <notifications use="default"/> </domain> <domain type="user" snaps="0" lin="0x0000000100020596" id="2002"> <id-name>nick</id-name> <usage resource="physical">1001984</usage> <usage resource="logical">483743</usage> <usage resource="inodes">12</usage> <path>/ifs/home/nick</path> <enforcements default-resource="logical"> <enforcement type="soft" resource="logical"> <limit>10485760</limit> <grace>7776000</grace> </enforcement> <enforcement type="advisory" resource="logical"> <limit>5242880</limit> </enforcement> </enforcements> <notifications> <quota-notify-map tag="1"></quota-notify-map> </notifications> </domain> </domains> </quota-report>
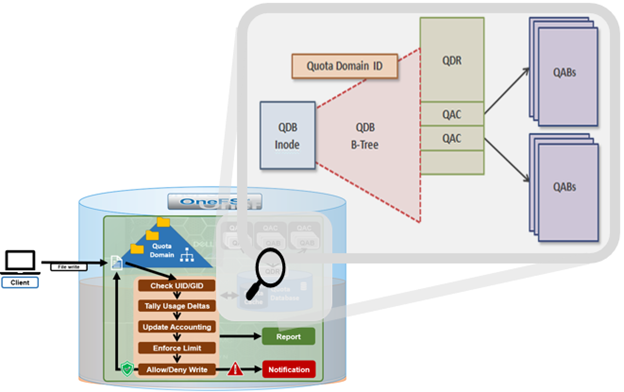
When listing domains, both inode and path, as well as name and ID, are stored with each domain. Quota Notification Rules are read and inserted into a domain entry only if the domain is not inherited to avoid any performance impact of reading the Quota Notification Rules with each domain.
SmartQuotas can be configured to produce scheduled reports to help monitor, track, and analyze storage use on a OneFS powered cluster.
Quota reports are managed by configuring settings that provide control over when reports are scheduled, how they are generated, where and how many are stored and how they are viewed. The maximum number of scheduled reports that are available for viewing in the web-administration interface can be configured for each report type. When the maximum number of reports is stored, the system automatically deletes the oldest reports to make space for new reports as they are generated.
SmartQuotas can be easily configured to generate quota report settings to generate the quota report on a specified schedule. These settings determine whether and when scheduled reports are generated, and where and how the reports are stored. Even if scheduled reports are disabled, you can still run unscheduled reports at any time.
The method to do this is:
- From the OneFS WebUI, go to File System Management > SmartQuotas > Settings.
- (Optional) On the Quota settings page, for Scheduled Reporting, click On. The Report Frequency option appears.
- Click Change schedule and select the report frequency that you want to set from the list.
- Select the reporting schedule options that you want.
- Click Save.
Reports are generated according to your criteria and can be viewed in the Generated Reports Archive.
In addition to scheduled quota reports, you can generate a report to capture usage statistics at a point in time. Before you can generate a quota report, quotas must exist and no QuotaScan jobs can be running.
The following procedure will achieve this:
- Click File System Management > SmartQuotas > Generated Reports Archive.
- In the Generated Quota Reports Archive area, click Generate a quota report.
- Click Generate Report.
The new report appears in the Quota Reports list.
You can locate quota reports, which are stored as XML files, and use your own tools and transforms to view them. This task can only be performed from the OneFS command-line interface.
A procedure for this is as follows:
- Open a secure shell (SSH) connection to any node in the cluster and log in.
- Go to the directory where quota reports are stored. The following path is the default quota report location:
/ifs/.isilon/smartquotas/reports
If quota reports are not in the default directory, you can run the isi quota settings command to find the directory where they are stored.
- At the command prompt, run the ls command.
To view a list of all quota reports in the directory, run the following command:
# ls -a *.xml
To view a specific quota report in the directory, run the following command:
# ls <filename>.xml