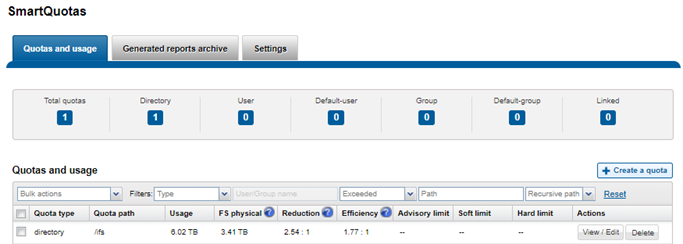
Amongst the myriad of new features that are introduced in the OneFS 9.5 release is SupportAssist, Dell’s next-gen remote connectivity system.
Dell SupportAssist helps rapidly identify, diagnose, and resolve cluster issues fast, and provides the following key benefits:
- Improve productivity by replacing manual routines with automated support.
- Accelerate resolution, or avoid issues completely, with predictive issue detection and proactive remediation.
- SupportAssist is included with all support plans (features vary based on service level agreement).
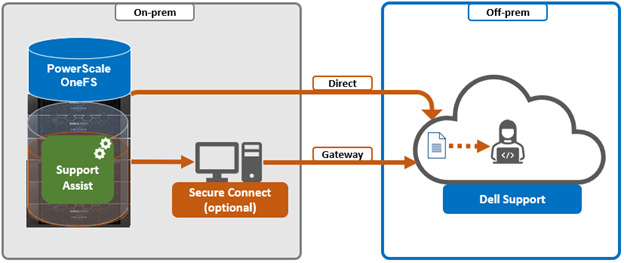
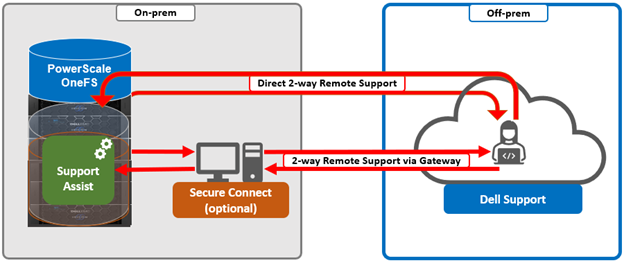
Within OneFS, SupportAssist is intended for transmitting events, logs, and telemetry from PowerScale to Dell support. As such, it provides a full replacement for the legacy ESRS.
Delivering a consistent remote support experience across the Dell storage portfolio, SupportAssist is intended for all sites that can send telemetry off-cluster to Dell over the internet. SupportAssist integrates the Dell Embedded Service Enabler (ESE) into PowerScale OneFS along with a suite of daemons to allow its use on a distributed system
| SupportAssist | ESRS |
| Dell’s next generation remote connectivity solution. | Being phased out of service. |
| Can either connect directly, or via supporting gateways. | Can only use gateways for remote connectivity. |
| Uses Connectivity Hub to coordinate support. | Uses ServiceLink to coordinate support. |
| Requires access key and pin, or hardware key, to enable. | Uses customer username and password to enable. |
SupportAssist uses Dell Connectivity Hub and can either interact directly, or through a Secure Connect gateway.
SupportAssist comprises a variety of components that gather and transmit various pieces of OneFS data and telemetry to Dell Support, via the Embedded Service Enabler (ESE). These workflows include CELOG events, In-product activation (IPA) information, CloudIQ telemetry data, Isi-Gather-info (IGI) logsets, and provisioning, configuration and authentication data to ESE and the various backend services.
| Operation | Details |
| Event Notification | In OneFS 9.5, SupportAssist can be configured to send CELOG events and attachments via ESE to CLM. CELOG has a ‘supportassist’ channel that, when active, will create an EVENT task for SupportAssist to propagate. |
| License Activation | The isi license activation start command uses SupportAssist to connect.
Several pieces of PowerScale and OneFS functionality require licenses, and to register and must communicate with the Dell backend services in order to activate those cluster licenses. In OneFS 9.5, SupportAssist is the preferred mechanism to send those license activations via the Embedded Service Enabler(ESE) to the Dell backend. License information can be generated via the ‘isi license generate’ CLI command, and then activated via the ‘isi license activation start’ syntax. |
| Provisioning | SupportAssist must register with backend services in a process known as provisioning. This process must be executed before the Embedded Service Enabler(ESE) will respond on any of its other available API endpoints. Provisioning can only successfully occur once per installation, and subsequent provisioning tasks will fail. SupportAssist must be configured via the CLI or WebUI before provisioning. The provisioning process uses authentication information that was stored in the key manager upon the first boot. |
| Diagnostics | The OneFS isi diagnostics gather and isi_gather_info logfile collation and transmission commands have a –supportassist option. |
| Healthchecks | HealthCheck definitions are updated using SupportAssist. |
| Telemetry | CloudIQ Telemetry data is sent using SupportAssist. |
| Remote Support | Remote Support uses SupportAssist and the Connectivity Hub to assist customers with their clusters. |
SupportAssist requires an access key and PIN, or hardware key, in order to be enabled, with most customers likely using the access key and pin method. Secure keys are held in Key manager under the RICE domain.
In addition to the transmission of data from the cluster to Dell, Connectivity Hub also allows inbound remote support sessions to be established for remote cluster troubleshooting.
In the next article in this series, we’ll take a deeper look at the SupportAssist architecture and operation.