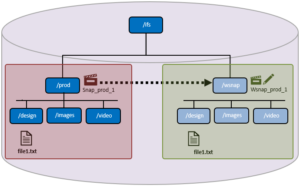
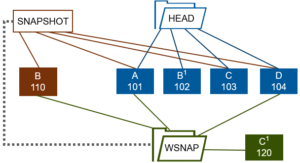
When it comes to the monitoring and management of OneFS writable snaps, the ‘isi writable snapshots’ CLI syntax looks and feels similar to regular, read-only snapshots utilities. The currently available writable snapshots on a cluster can be easily viewed from the CLI with the ‘isi snapshot writable list’ command. For example:
# isi snapshot writable list Path Src Path Src Snapshot ---------------------------------------------- /ifs/test/wsnap1 /ifs/test/prod prod1 /ifs/test/wsnap2 /ifs/test/snap2 s73736 ----------------------------------------------
The properties of a particular writable snap, including both its logical and physical size, can be viewed using the ‘isi snapshot writable view’ CLI command:
# isi snapshot writable view /ifs/test/wsnap1 Path: /ifs/test/wsnap1 Src Path: /ifs/test/prod Src Snapshot: s73735 Created: 2021-06-11T19:10:25 Logical Size: 100.00 Physical Size: 32.00k State: active
The capacity resource accounting layer for writable snapshots is provided by OneFS SmartQuotas. Physical, logical, and application logical space usage is retrieved from a directory quota on the writable snapshot’s root and displayed via the CLI as follows:
# isi quota quotas list Type AppliesTo Path Snap Hard Soft Adv Used Reduction Efficiency ----------------------------------------------------------------------------------------- directory DEFAULT /ifs/test/wsnap1 No - - - 76.00 - 0.00 : 1 -----------------------------------------------------------------------------------------
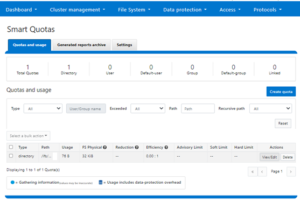
Or from the OneFS WebUI by navigating to File system > SmartQuotas > Quotas and usage:
For more detail, the ‘isi quota quotas view’ CLI command provides a thorough appraisal of a writable snapshot’s directory quota domain, including physical, logical, and storage efficiency metrics plus a file count. For example:
# isi quota quotas view /ifs/test/wsnap1 directory Path: /ifs/test/wsnap1 Type: directory Snapshots: No Enforced: Yes Container: No Linked: No Usage Files: 10 Physical(With Overhead): 32.00k FSPhysical(Deduplicated): 32.00k FSLogical(W/O Overhead): 76.00 AppLogical(ApparentSize): 0.00 ShadowLogical: - PhysicalData: 0.00 Protection: 0.00 Reduction(Logical/Data): None : 1 Efficiency(Logical/Physical): 0.00 : 1 Over: - Thresholds On: fslogicalsize ReadyToEnforce: Yes Thresholds Hard Threshold: - Hard Exceeded: No Hard Last Exceeded: - Advisory: - Advisory Threshold Percentage: - Advisory Exceeded: No Advisory Last Exceeded: - Soft Threshold: - Soft Threshold Percentage: - Soft Exceeded: No Soft Last Exceeded: - Soft Grace: -
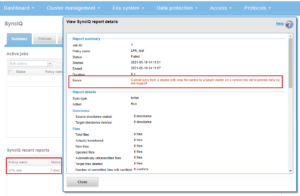
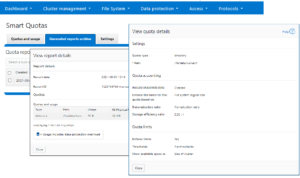
This information is also available from the OneFS WebUI by navigating to File system > SmartQuotas > Generated reports archive > View report details:
Additionally, the ‘isi get’ CLI command can be used to inspect the efficiency of individual writable snapshot files. First, run the following command syntax on the chosen file in the source snapshot path (in this case /ifs/test/source).
In the example below, the source file, /ifs//test/prod/testfile1, is reported as 147 MB in size and occupying 18019 physical blocks:
# isi get -D /ifs/test/prod/testfile1.zip POLICY W LEVEL PERFORMANCE COAL ENCODING FILE IADDRS default 16+2/2 concurrency on UTF-8 testfile1.txt <1,9,92028928:8192> ************************************************* * IFS inode: [ 1,9,1054720:512 ] ************************************************* * * Inode Version: 8 * Dir Version: 2 * Inode Revision: 145 * Inode Mirror Count: 1 * Recovered Flag: 0 * Restripe State: 0 * Link Count: 1 * Size: 147451414 * Mode: 0100700 * Flags: 0x110000e0 * SmartLinked: False * Physical Blocks: 18019
However, when running the ‘isi get’ CLI command on the same file within the writable snapshot tree (/ifs/test/wsnap1/testfile1), the writable, space-efficient copy now only consumes 5 physical blocks, as compared with 18019 blocks in the original file:
# isi get -D /ifs/test/wsnap1/testfile1.zip POLICY W LEVEL PERFORMANCE COAL ENCODING FILE IADDRS default 16+2/2 concurrency on UTF-8 testfile1.txt <1,9,92028928:8192> ************************************************* * IFS inode: [ 1,9,1054720:512 ] ************************************************* * * Inode Version: 8 * Dir Version: 2 * Inode Revision: 145 * Inode Mirror Count: 1 * Recovered Flag: 0 * Restripe State: 0 * Link Count: 1 * Size: 147451414 * Mode: 0100700 * Flags: 0x110000e0 * SmartLinked: False * Physical Blocks: 5
Writable snaps use the OneFS policy domain manager, or PDM, for domain membership checking and verification. For each writable snap, a ‘WSnap’ domain is created on the target directory. The ‘isi_pdm’ CLI utility can be used to report on the writable snapshot domain for a particular directory.
# isi_pdm -v domains list --patron Wsnap /ifs/test/wsnap1 Domain Patron Path b.0700 WSnap /ifs/test/wsnap1
Additional details of the backing domain can also be displayed with the following CLI syntax:
# isi_pdm -v domains read b.0700
('b.0700',):
{ version=1 state=ACTIVE ro store=(type=RO SNAPSHOT, ros_snapid=650, ros_root=5:23ec:0011)ros_lockid=1) }
Domain association does have some ramifications for writable snapshots in OneFS 9.3 and there are a couple of notable caveats. For example, files within the writable snapshot domain cannot be renamed outside of the writable snap to allow the file system to track files in a simple manner.
# mv /ifs/test/wsnap1/file1 /ifs/test mv: rename file1 to /ifs/test/file1: Operation not permitted
Also, the nesting of writable snaps is not permitted in OneFS 9.3, and an attempt to create a writable snapshot on a subdirectory under an existing writable snapshot will fail with the following CLI command warning output:
# isi snapshot writable create prod1 /ifs/test/wsnap1/wsnap1-2 Writable snapshot:/ifs/test/wsnap1 nested below another writable snapshot: Operation not supported
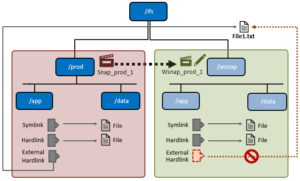
When a writable snap is created, any existing hard links and symbolic links (symlinks) that reference files within the snapshot’s namespace will continue to work as expected. However, existing hard links with a file external to the snapshot’s domain will disappear from the writable snap, including the link count.
| Link Type | Supported | Details |
| Existing external hard link | No | Old external hard links will fail. |
| Existing internal hard link | Yes | Existing hard links within the snapshot domain will work as expected. |
| External hard link | No | New external hard links will fail. |
| New internal hard link | Yes | Existing hard links will work as expected. |
| External symbolic link | Yes | External symbolic links will work as expected. |
| Internal symbolic link | Yes | Internal symbolic links will work as expected. |
Be aware that any attempt to create a hard link to another file outside of the writable snapshot boundary will fail.
# ln /ifs/test/file1 /ifs/test/wsnap1/file1 ln: /ifs/test/wsnap1/file1: Operation not permitted
However, symbolic links will work as expected. OneFS hard link and symlink actions and expectations with writable snaps are as follows:
Writable snaps do not have a specific license, and their use is governed by the OneFS SnapshotIQ data service. As such, in addition to a general OneFS license, SnapshotIQ must be licensed across all the nodes in order to use writable snaps on a OneFS 9.3 PowerScale cluster. Additionally, the ‘ISI_PRIV_SNAPSHOT’ role-based administration privilege is required on any cluster administration account that will create and manage writable snapshots. For example:
# isi auth roles view SystemAdmin | grep -i snap ID: ISI_PRIV_SNAPSHOT
In general, writable snapshot file access is marginally less performant compared to the source, or head, files, since an additional level of indirection is required to access the data blocks. This is particularly true for older source snapshots, where a lengthy read-chain can require considerable ‘ditto’ block resolution. This occurs when parts a file no longer resides in the source snapshot, and the block tree of the inode on the snapshot does not point to a real data block. Instead it has a flag marking it as a ‘ditto block’. A Ditto-block indicates that the data is the same as the next newer version of the file, so OneFS automatically looks ahead to find the more recent version of the block. If there are large numbers (such as hundreds or thousands) of snapshots of the same unchanged file, reading from the oldest snapshot can have a considerable impact on latency.
| Performance Attribute | Details |
| Large Directories | Since a writable snap performs a copy-on-read to populate file metadata on first access, the initial access of a large directory (containing millions of files, for example) that tries to enumerate its contents will be relatively slow because the writable snapshot has to iteratively populate the metadata. This is applicable to namespace discovery operations such as ‘find’ and ‘ls’, unlinks and renames, plus other operations working on large directories. However, any subsequent access of the directory or its contents will be fast since file metadata will already be present and there will be no copy-on-read overhead.
The unlink_copy_batch & readdir_copy_batch parameters under the sysctl ‘efs.wsnap’ control of the size of batch metadata copy operations. These parameters can be helpful for tuning the number of iterative metadata copy-on-reads for datasets containing large directories. However, these sysctls should only be modified under the direct supervision of Dell technical support. |
| Writable snapshot metadata read/write | Initial read and write operations will perform a copy-on-read and will therefore be marginally slower compared to the head. However, once the copy-on-read has been performed for the LINs, the performance of read/write operations will be nearly equivalent to head. |
| Writable snapshot data read/write | In general, writable snapshot data reads and writes will be slightly slower compared to head. |
| Multiple writable snapshots of single source | The performance of each subsequent writable snap created from the same source read-only snapshot will be the same as that of the first, up to the OneFS 9.3 default recommended limit of a total of 30 writable snapshots. This is governed by the ‘max_active_wsnpas’ sysctl.
# sysctl efs.wsnap.max_active_wsnaps efs.wsnap.max_active_wsnaps: 30 While the ‘max_active_wsnaps’ sysctl can be configured up to a maximum of 2048 writable snapshots per cluster, changing this sysctl from its default value of 30 is strongly discouraged in OneFS 9.3.
|
| Writable snapshots and SmartPools tiering | Since unmodified file data in a writable snap is read directly from the source snapshot, if the source is stored on a lower performance tier than the writable snapshot’s directory structure this will negatively impact the writable snapshot’s latency. |
| Storage Impact | The storage capacity consumption of a writable snapshot is proportional to the number of writes, truncate, or similar operations it receives, since only the changed blocks relative to its source snapshot are stored. The metadata overhead will grow linearly as a result of copy-on-reads with each new writable snapshots that is created and accessed. |
| Snapshot Deletes | Writable snapshot deletes are de-staged and performed out of band by the TreeDelete job. As such, the performance impact should be minimal, although the actual delete of the data is not instantaneous. Additionally, the TreeDelete job has a path to avoid copy-on-writing any files within a writable snap that have yet to been enumerated. |
Be aware that, since writable snaps are highly space efficient, the savings are strictly in terms of file data. This means that metadata will be consumed in full for each file and directory in a snapshot. So, for large sizes and quantities of writable snapshots, inode consumption should be considered, especially for metadata read and metadata write SSD strategies.
In the next and final article in this series, we’ll examine writable snapshots in the context of the other OneFS data services.