In this article, we’ll take a quick look at the OneFS journal and boot drive mirroring functionality in PowerScale chassis-based hardware:
PowerScale Gen6 platforms, such as the H700/7000 and A300/3000, stores the local filesystem journal and its mirror in the DRAM of the battery backed compute node blade. Each 4RU Gen 6 chassis houses four nodes. These nodes comprise a ‘compute node blade’ (CPU, memory, NICs), plus drive containers, or sleds, for each.
A node’s file system journal is protected against sudden power loss or hardware failure by OneFS’ journal vault functionality – otherwise known as ‘powerfail memory persistence’ (PMP). PMP automatically stores the both the local journal and journal mirror on a separate flash drive across both nodes in a node pair:
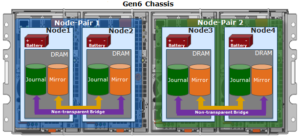
This journal de-staging process is known as ‘vaulting’, during which the journal is protected by a dedicated battery in each node until it’s safely written from DRAM to SSD on both nodes in a node-pair. With PMP, constant power isn’t required to protect the journal in a degraded state since the journal is saved to M.2 flash, and mirrored on the partner node.
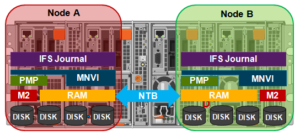
So, the mirrored journal is comprised of both hardware and software components, including the following constituent parts:
Journal Hardware Components
- System DRAM
- 2 Vault Flash
- Battery Backup Unit (BBU)
- Non-Transparent Bridge (NTB) PCIe link to partner node
- Clean copy on disk
Journal Software Components
- Power-fail Memory Persistence (PMP)
- Mirrored Non-volatile Interface (MNVI)
- IFS Journal + Node State Block (NSB)
- Utilities
Asynchronous DRAM Refresh (ADR) preserves RAM contents when the operating system is not running. ADR is important for preserving RAM journal contents across reboots, and it does not require any software coordination to do so.
The journal vault feature encompasses the hardware, firmware, and operating system support that ensure the journal’s contents are preserved across power failure. The mechanism is similar to the NVRAM controller on previous generation nodes, but does not use a dedicated PCI card.

On power failure, the PMP vaulting functionality is responsible for copying both the local journal and the local copy of the partner node’s journal to persistent flash. On restoration of power, PMP is responsible for restoring the contents of both journals from flash to RAM, and notifying the operating system.
A single dedicated flash device is attached via M.2 slot on the motherboard of the node’s compute module, residing under the battery backup unit (BBU) pack. To be serviced, the entire compute module must be removed.

If the M.2 flash needs to be replaced for any reason, it will be properly partitioned and the PMP structure will be created as part of arming the node for vaulting.
The battery backup unit (BBU), when fully charged, provides enough power to vault both the local and partner journal during a power failure event.

A single battery is utilized in the BBU, which also supports back-to-back vaulting.
On the software side, the journal’s Power-fail Memory Persistence (PMP) provides an equivalent to the NVRAM controller‘s vault/restore capabilities to preserve Journal. The PMP partition on the M.2 flash drive provides an interface between the OS and firmware.
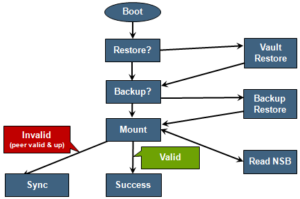
If a node boots and its primary journal is found to be invalid for whatever reason, it has three paths for recourse:
- Recover journal from its M.2 vault.
- Recover journal from its disk backup copy.
- Recover journal from its partner node’s mirrored copy.
The mirrored journal must guard against rolling back to a stale copy of the journal on reboot. This necessitates storing information about the state of journal copies outside the journal. As such, the Node State Block (NSB) is a persistent disk block that stores local and remote journal status (clean/dirty, valid/invalid, etc), as well as other non-journal information. NSB stores this node status outside the journal itself, and ensures that a node does not revert to a stale copy of the journal upon reboot.
Here’s the detail of an individual node’s compute module:
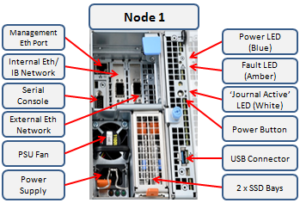
Of particular note is the ‘journal active’ LED, which is displayed as a white ‘hand icon’.

When this white hand icon is illuminated, it indicates that the mirrored journal is actively vaulting, and it is not safe to remove the node!
There is also a blue ‘power’ LED, and a yellow ‘fault’ LED per node. If the blue LED is off, the node may still be in standby mode, in which case it may still be possible to pull debug information from the baseboard management controller (BMC).
The flashing yellow ‘fault’ LED has several state indication frequencies:
| Blink Speed | Blink Frequency | Indicator |
| Fast blink | ¼ Hz | BIOS |
| Medium blink | 1 Hz | Extended POST |
| Slow blink | 4 Hz | Booting OS |
| Off | Off | OS running |
The mirrored non-volatile interface (MNVI) sits below /ifs and above RAM and the NTB, provides the abstraction of a reliable memory device to the /ifs journal. MNVI is responsible for synchronizing journal contents to peer node RAM, at the direction of the journal, and persisting writes to both systems while in a paired state. It upcalls into the journal on NTB link events, and notifies the journal of operation completion (mirror sync, block IO, etc).
For example, when rebooting after a power outage, a node automatically loads the MNVI. It then establishes a link with its partner node and synchronizes its journal mirror across the PCIe Non-Transparent Bridge (NTB).
Prior to mounting /ifs, OneFS locates a valid copy of the journal from one of the following locations in order of preference:
| Order | Journal Location | Description |
| 1st | Local disk | A local copy that has been backed up to disk |
| 2nd | Local vault | A local copy of the journal restored from Vault into DRAM |
| 3rd | Partner node | A mirror copy of the journal from the partner node |
If the node was shut down properly, it will boot using a local disk copy of the journal. The journal will be restored into DRAM and /ifs will mount. On the other hand, if the node suffered a power disruption the journal will be restored into DRAM from the M.2 vault flash instead (the PMP copies the journal into the M.2 vault during a power failure).
In the event that OneFS is unable to locate a valid journal on either the hard drives or M.2 flash on a node, it will retrieve a mirrored copy of the journal from its partner node over the NTB. This is referred to as ‘Sync-back’.
Note: Sync-back state only occurs when attempting to mount /ifs.
On booting, if a node detects that its journal mirror on the partner node is out of sync (invalid), but the local journal is clean, /ifs will continue to mount. Subsequent writes are then copied to the remote journal in a process known as ‘sync-forward’.
Here’s a list of the primary journal states:
| Journal State | Description |
| Sync-forward | State in which writes to a journal are mirrored to the partner node. |
| Sync-back | Journal is copied back from the partner node. Only occurs when attempting to mount /ifs. |
| Vaulting | Storing a copy of the journal on M.2 flash during power failure. Vaulting is performed by PMP. |
During normal operation, writes to the primary journal and its mirror are managed by the MNVI device module, which writes through local memory to the partner node’s journal via the NTB. If the NTB is unavailable for an extended period, write operations can still be completed successfully on each node. For example, if the NTB link goes down in the middle of a write operation, the local journal write operation will complete. Read operations are processed from local memory.
Additional journal protection for Gen 6 nodes is provided by OneFS’ powerfail memory persistence (PMP) functionality, which guards against PCI bus errors that can cause the NTB to fail. If an error is detected, the CPU requests a ‘persistent reset’, during which the memory state is protected and node rebooted. When back up again, the journal is marked as intact and no further repair action is needed.
If a node looses power, the hardware notifies the BMC, initiating a memory persistent shutdown. At this point the node is running on battery power. The node is forced to reboot and load the PMP module, which preserves its local journal and its partner’s mirrored journal by storing them on M.2 flash. The PMP module then disables the battery and powers itself off.
Once power is back on and the node restarted, the PMP module first restores the journal before attempting to mount /ifs. Once done, the node then continues through system boot, validating the journal, setting sync-forward or sync-back states, etc.
During boot, isi_checkjournal and isi_testjournal will invoke isi_pmp. If the M.2 vault devices are unformatted, isi_pmp will format the devices.
On clean shutdown, isi_save_journal stashes a backup copy of the /dev/mnv0 device on the root filesystem, just as it does for the NVRAM journals in previous generations of hardware.
If a mirrored journal issue is suspected, or notified via cluster alerts, the best place to start troubleshooting is to take a look at the node’s log events. The journal logs to /var/log/messages, with entries tagged as ‘journal_mirror’.
The following new CELOG events have also been added in OneFS 8.1 for cluster alerting about mirrored journal issues:
| CELOG Event | Description |
| HW_GEN6_NTB_LINK_OUTAGE | Non-transparent bridge (NTP) PCIe link is unavailable |
| FILESYS_JOURNAL_VERIFY_FAILURE | No valid journal copy found on node |
Another reliability optimization for the Gen6 platform is boot mirroring. Gen6 does not use dedicated bootflash devices, as with previous generation nodes. Instead, OneFS boot and other OS partitions are stored on a node’s data drives. These OS partitions are always mirrored (except for crash dump partitions). The two mirrors protect against disk sled removal. Since each drive in a disk sled belongs to a separate disk pool, both elements of a mirror cannot live on the same sled.
The boot and other OS partitions are 8GB and reserved at the beginning of each data drive for boot mirrors. OneFS automatically rebalances these mirrors in anticipation of, and in response to, service events. Mirror rebalancing is triggered by drive events such as suspend, softfail and hard loss.
The following command will confirm that boot mirroring is working as intended:
# isi_mirrorctl verify
When it comes to smartfailing nodes, here are a couple of other things to be aware of with mirror journal and the Gen6 platform:
- When you smartfail a node in a node pair, you do not have to smartfail its partner node.
- A node will still run indefinitely with its partner missing. However, this significantly increases the window of risk since there’s no journal mirror to rely on (in addition to lack of redundant power supply, etc).
- If you do smartfail a single node in a pair, the journal is still protected by the vault and powerfail memory persistence.
Regarding the journal’s Battery Backup Unit (BBU), later versions of OneFS and BBU firmware can generate an Cell End of Life warning. This end-of-life message (EOL) for the BBU does not indicate that the BBU is unhealthy, but rather that it’s coming up on EOL.
The battery wear percentage value indicates the amount of deterioration to the battery cell and therefore its ability hold charge.
The BBU firmware version 2.20 introduced an alert that will warns when a node is approaching End of Life (EOL) on its battery. The report for the event will occur when battery degradation reaches a 40% threshold.
Note that a nodes will automatically transition into read-only (RO) state if the battery reaches the 50% threshold.
A cluster’s BBU firmware version can be easily determined via the following CLI syntax:
# isi upgrade cluster firmware devices | egrep "mongoose|bcc"
The command output will be similar to the following:
# isi upgrade cluster firmware devices| egrep "mongoose|bcc" MLKbem_mongoose ePOST 02.40 1-4 EPbcc_infinity ePOST 02.40 5-8
The amount of time to go from 40% degradation to 50% degradation is also affected by the BBU firmware version. If the BBU firmware version is 1.20, the battery should take four months to go from 40% to 50% degradation
If the BBU firmware version is 2.20 or above, the battery should take 12 months to transition from 40% to 50% degradation.
Details about upgrading from BBU firmware version 1.20 to the latest supported firmware version can be found in the following KB article.