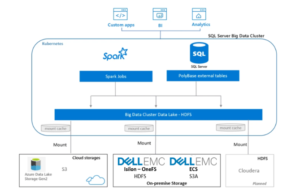
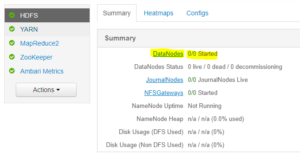
The following are known issues that exist with OneFS and Hadoop HDFS integrations:
Oozie sharedlib deployment fails with Isilon
The deployment of the oozie shared libraries fails on Ambari 2.7/HDP 3.x against Isilon.
oozie makes a rpc check for erasure encoding when deploying the shared libararies, OneFS doesn’t support HDFS erasure encoding as OneFS is natively using its own Erasure Encoding for data protection and the call fails with poor handling on the oozie side of the code, this causes a failure in the deployment of the shared lib.
[root@centos-01 ~]# /usr/hdp/current/oozie-server/bin/oozie-setup.sh sharelib create -fs hdfs://hdp-27.foo.com:8020 -locallib /usr/hdp/3.0.1.0-187/oozie/libserver
setting OOZIE_CONFIG=${OOZIE_CONFIG:-/usr/hdp/current/oozie-server/conf}
setting CATALINA_BASE=${CATALINA_BASE:-/usr/hdp/current/oozie-server/oozie-server}
setting CATALINA_TMPDIR=${CATALINA_TMPDIR:-/var/tmp/oozie}
setting OOZIE_CATALINA_HOME=/usr/lib/bigtop-tomcat
setting JAVA_HOME=/usr/jdk64/jdk1.8.0_112
setting JRE_HOME=${JAVA_HOME}
setting CATALINA_OPTS="$CATALINA_OPTS -Xmx2048m"
setting OOZIE_LOG=/var/log/oozie
setting CATALINA_PID=/var/run/oozie/oozie.pid
setting OOZIE_DATA=/hadoop/oozie/data
setting OOZIE_HTTP_PORT=11000
setting OOZIE_ADMIN_PORT=11001
setting JAVA_LIBRARY_PATH=/usr/hdp/3.0.1.0-187/hadoop/lib/native/Linux-amd64-64
setting OOZIE_CLIENT_OPTS="${OOZIE_CLIENT_OPTS} -Doozie.connection.retry.count=5 "
setting OOZIE_CONFIG=${OOZIE_CONFIG:-/usr/hdp/current/oozie-server/conf}
setting CATALINA_BASE=${CATALINA_BASE:-/usr/hdp/current/oozie-server/oozie-server}
setting CATALINA_TMPDIR=${CATALINA_TMPDIR:-/var/tmp/oozie}
setting OOZIE_CATALINA_HOME=/usr/lib/bigtop-tomcat
setting JAVA_HOME=/usr/jdk64/jdk1.8.0_112
setting JRE_HOME=${JAVA_HOME}
setting CATALINA_OPTS="$CATALINA_OPTS -Xmx2048m"
setting OOZIE_LOG=/var/log/oozie
setting CATALINA_PID=/var/run/oozie/oozie.pid
setting OOZIE_DATA=/hadoop/oozie/data
setting OOZIE_HTTP_PORT=11000
setting OOZIE_ADMIN_PORT=11001
setting JAVA_LIBRARY_PATH=/usr/hdp/3.0.1.0-187/hadoop/lib/native/Linux-amd64-64
setting OOZIE_CLIENT_OPTS="${OOZIE_CLIENT_OPTS} -Doozie.connection.retry.count=5 "
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/hdp/3.0.1.0-187/oozie/lib/slf4j-simple-1.6.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdp/3.0.1.0-187/oozie/libserver/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/hdp/3.0.1.0-187/oozie/libserver/slf4j-log4j12-1.6.6.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.SimpleLoggerFactory]
3138 [main] WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
4193 [main] INFO org.apache.hadoop.security.UserGroupInformation - Login successful for user oozie/centos-01.foo.com@FOO.COM using keytab file /etc/security/keytabs/oozie.service.keytab
4436 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.local.dir is deprecated. Instead, use mapreduce.cluster.local.dir
4490 [main] INFO org.apache.hadoop.security.SecurityUtil - Updating Configuration
log4j:WARN No appenders could be found for logger (org.apache.htrace.core.Tracer).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
Found Hadoop that supports Erasure Coding. Trying to disable Erasure Coding for path: /user/root/share/lib
Error invoking method with reflection
Error: java.lang.reflect.InvocationTargetException
Stack trace for the error was (for debug purposes):
java.lang.RuntimeException: java.lang.reflect.InvocationTargetException
at org.apache.oozie.tools.ECPolicyDisabler.invokeMethod(ECPolicyDisabler.java:111)
at org.apache.oozie.tools.ECPolicyDisabler.tryDisableECPolicyForPath(ECPolicyDisabler.java:47)
at org.apache.oozie.tools.OozieSharelibCLI.run(OozieSharelibCLI.java:171)
at org.apache.oozie.tools.OozieSharelibCLI.main(OozieSharelibCLI.java:67)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.oozie.tools.ECPolicyDisabler.invokeMethod(ECPolicyDisabler.java:108)
... 3 more
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.RpcNoSuchMethodException): Unknown RPC: getErasureCodingPolicy
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1497)
at org.apache.hadoop.ipc.Client.call(Client.java:1443)
at org.apache.hadoop.ipc.Client.call(Client.java:1353)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy9.getErasureCodingPolicy(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getErasureCodingPolicy(ClientNamenodeProtocolTranslatorPB.java:1892)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy10.getErasureCodingPolicy(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.getErasureCodingPolicy(DFSClient.java:3082)
at org.apache.hadoop.hdfs.DistributedFileSystem$66.doCall(DistributedFileSystem.java:2884)
at org.apache.hadoop.hdfs.DistributedFileSystem$66.doCall(DistributedFileSystem.java:2881)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getErasureCodingPolicy(DistributedFileSystem.java:2898)
... 8 more
A workaround is a manual copy and unpack of the oozie-sharelib.tar.gz to the /user/oozie/share/lib
Cloudera BDR integration with Cloudera Manager Based Isilon Integration
Cloudera CDH with BDR is no longer supported with Isilon, CDH fails to integrate BDR completely with a Cloudera Manager based Isilon cluster.
Upgrading Ambari 2.6.5 to 2.7 – setfacl issue with Hive
Per the following procedure: http://www.unstructureddatatips.com/upgrade-hortonworks-hdp2-6-5-to-hdp3-on-dellemc-isilon-onefs-8-1-2-and-later/
When upgrading from Ambari 2.6.5 to 2.7, if the Hive Service is installed the following must be completed prior to upgrade otherwise the upgrade process will stall with an Unknown RPC issue as seen below.
The Isilon OneFS HDFS service does not support the HDFS ACL’s and the resulting setfacl will cause the upgrade to stall.
Add the following property: dfs.namenode.acls.enabled=false to the custom hdfs-site prior to upgrading and this will prevent the upgrade attempting to use setfacl.
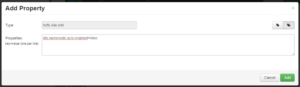
Restart any services that need restarting

Execute the upgrade per the procedure and the Hive setfacl issue will not be encountered.
Additional Upgrade issue you may see:
– Error mapping uname \’yarn-ats\’ to uid (created yarn-ats user: isi auth users create yarn-ats –zone=<hdfs zone>)
– MySQL Dependency error (execute: ambari-server setup –jdbc-db=mysql –jdbc-driver=/usr/share/java/mysql-connector-java.jar)
– Ambari Metrics restart issue Reference: http://www.ryanchapin.com/fv-b-4-818/-SOLVED–Unable-to-Connect-to-ambari-metrics-collector-Issues.html
OneFS 8.2 Local Service Accounts need to be ENABLED
With the release of OneFS 8.2 a number of changes were made in the identity management stack, one modification that is required on 8.2 is that local accounts need to be in the enabled state to be used for identity, in prior version local account ID’s could be used with the local account disabled.
In 8.2 all local accounts must be ENABLED to be used for ID management by OneFS, this is required:
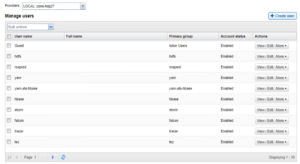
In 8.1.2 and prior, local accounts were functional when disabled
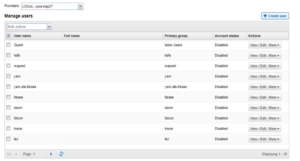
On upgrade to 8.2
- All accounts should be set the ‘enabled state’
- Enable all accounts prior to upgrade
The latest version of the create_users script on the isilon_hadoop_tools github will now create enabled users by default
Enabling account does not make this account interactive logon aware they are still just ID’s used by Isilon for HDFS ID management.
Support for HDP 3.1 with the Isilon Management Pack 1.0.1.0
With the release of the Isilon Management Pack 1.0.1.0 support for HDP 3.1 is included, the procedure to upgrade the mpack is listed here if mpack 1.0.0.1 was installed with HDP 3.0.1.
Before upgrading the mpack the following KB should be consulted to assess the status of the Kerberized Spark2 services and if modifications were made to 3.0.1 installs were made in Ambari: Isilon: Spark2 fails to start after Kerberization with HDP 3 and OneFS due to missing configurations
Upgrade the Isilon Ambari Management Pack
- Download the Isilon Ambari Management Pack
- Install the management pack by running the following commands on the
Ambari server:
ambari-server upgrade-mpack –-mpack = <path-to-new-mpack.tar.gz> -verbose
ambari-server restart
How to determine the Isilon Ambari Management Pack version
On the Ambari server host run the following command:
ls /var/lib/ambari-server/resources/mpacks | grep “onefs-ambari-mpack-”
The output will appear similar to this, where x.x.x.x indicates which version of the IAMP is currently installed:
onefs-ambari-mpack-x.x.x.x
How to find the README in Isilon Ambari Management Pack 1.0.1.0
Download the Isilon Ambari Management Pack
- Run the following command to extract the contents:
- tar -zxvf isilon-onefs-mpack-1.0.1.0.tar.gz
- The README is located under isilon-onefs-mpack-1.0.1.0/addon-services/ONEFS/1.0.0/support/README
- Please review the README for release information.
The release of OneFS 8.2 brings changes to Hadoop Cluster Deployment and Setup
Prior to 8.2, the following two configurations were required to support Hadoop cluster
- Modification to the Access Control List Policy setting for OneFS is no longer needed
We used to run ‘isi auth settings acls modify –group-owner-inheritance=parent’ to make the OneFS file system act like an HDFS file system, this was a global setting and affected the whole cluster and other workflows. In 8.2 this is no longer needed, hdfs operation act like this natively so the setting is no longer required. Do not run this command on the setup of hdfs of new 8.2 clusters, if this was previously set on 8.1.2 and prior it is suggested to leave the setting as is because modifying it can affect other workflows.
- hdfs to root mappings is not needed – replaced by RBAC
Prior to 8.2 hdfs => root mappings were required to facilitate the behavior of the hdfs account, in 8.2 this root mapping has been replaced with an RBAC privilege, no root mapping is needed and instead the following RBAC role with the specified privileges should be created, add any account needing this access.
isi auth roles create --name=hdfs_access --description="Bypass FS permissions" --zone=System
isi auth roles modify hdfs_access --add-priv=ISI_PRIV_IFS_RESTORE --zone=System
isi auth roles modify hdfs_access --add-priv=ISI_PRIV_IFS_BACKUP --zone=System
isi auth roles modify hdfs_access --add-user=hdfs --zone=System
isi auth roles view hdfs_access --zone=System
isi_for_array "isi auth mapping flush --all"
isi_for_array "isi auth cache flush --all"
The installation guides will reflect these changes shortly.
Summary:
8.1.2 and Earlier:
hdfs=>root mapping
ACL Policy Change Needed
8.2 and Later
RBAC role for hdfs
No ACL Policy Change
When using Ambari 2.7 and the Isilon Management Pack, the following is seen in the Isilon hdfs.log:
isilon-3: 2019-05-14T14:34:06-04:00 <30.4> isilon-3 hdfs[95183]: [hdfs] Ambari: Agent for zone 12 got a bad exit code from its Ambari server. The agent will attempt to recover.
isilon-3: 2019-05-14T14:34:06-04:00 <30.6> isilon-3 hdfs[95183]: [hdfs] Ambari: The Ambari server for zone 12 is running a version unsupported by OneFS: 2.7.1.0. Agent will reset and retry until a supported Ambari server version is installed or Ambari is no longer enabled for this zone
isilon-3: 2019-05-14T14:35:12-04:00 <30.4> isilon-3 hdfs[95183]: [hdfs] Ambari: Agent for zone 12 got a bad exit code from its Ambari server. The agent will attempt to recover.
isilon-3: 2019-05-14T14:35:12-04:00 <30.6> isilon-3 hdfs[95183]: [hdfs] Ambari: The Ambari server for zone 12 is running a version unsupported by OneFS: 2.7.1.0. Agent will reset and retry until a supported Ambari server version is installed or Ambari is no longer enabled for this zone
isilon-3: 2019-05-14T14:36:17-04:00 <30.4> isilon-3 hdfs[95183]: [hdfs] Ambari: Agent for zone 12 got a bad exit code from its Ambari server. The agent will attempt to recover.
isilon-3: 2019-05-14T14:36:17-04:00 <30.6> isilon-3 hdfs[95183]: [hdfs] Ambari: The Ambari server for zone 12 is running a version unsupported by OneFS: 2.7.1.0. Agent will reset and retry until a supported Ambari server version is installed or Ambari is no longer enabled for this zone
When using Ambari with the Isilon Management Pack, Isilon should not be configured with an Ambari Server or ODP version as they are no longer needed since the Management Pack is in use.
If they have been added, remove them from the Isilon hdfs configuration for the zone in question, this only applied to Ambari 2.7 with the Isilon Management Pack, Ambari 2.6 and earlier still require these settings.
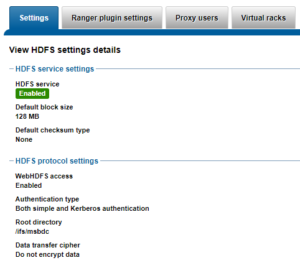
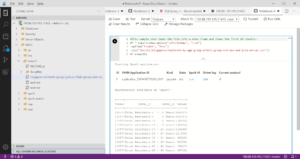
isilon-1# isi hdfs settings view --zone=zone-hdp27
Service: Yes
Default Block Size: 128M
Default Checksum Type: none
Authentication Mode: kerberos_only
Root Directory: /ifs/zone/hdp27/hadoop-root
WebHDFS Enabled: Yes
Ambari Server: -
Ambari Namenode: hdp-27.foo.com
Odp Version: -
Data Transfer Cipher: none
Ambari Metrics Collector: centos-01.foo.com
Ambari sees LDAPS issue connecting to AD during Kerberization
05 Apr 2018 20:05:14,081 ERROR [ambari-client-thread-38] KerberosHelperImpl:2379 - Cannot validate credentials: org.apache.ambari.server.serveraction.kerberos.KerberosInvalidConfigurationException: Failed to connect to KDC - Failed to communicate with the Active Directory at ldaps://rduvnode217745.west.isilon.com/DC=AMB3,DC=COM: simple bind failed: rduvnode217745.west.isilon.com:636
Make sure the server’s SSL certificate or CA certificates have been imported into Ambari’s truststore.
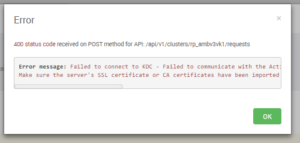
Review the following KB from Hortonworks on resolving this Ambari Issue:
https://community.hortonworks.com/content/supportkb/148572/failed-to-connect-to-kdc-make-sure-the-servers-ssl.html
HDFS rollup patch for 8.1.2 – Patch-240163:
Patch for OneFS 8.1.2.0. This patch addresses issues with the Hadoop Distributed File System (HDFS).
********************************************************************************
This patch can be installed on clusters running the following OneFS version:
8.1.2.0
This patch deprecates the following patch:
Patch-236288
This patch conflicts with the following patches:
Patch-237113
Patch-237483
If any conflicting or deprecated patches are installed on the cluster, you must
remove them before installing this patch.
********************************************************************************
RESOLVED ISSUES
* Bug ID 240177
The Hadoop Distributed File System (HDFS) rename command did not manage file
handles correctly and might have caused data unavailability with
STATUS_TOO_MANY_OPEN_FILES error.
* Bug ID 236286
If a OneFS cluster had the Hadoop Distributed File System (HDFS) configured for Kerberos authentication, WebHDFS requests over curl might have failed to follow a redirect request.
WebHDFS issue with Kerberized 8.1.2 – curl requests fail to follow redirects; Service Checks and Ambari Views will fail
Isilon HDFS error: STATUS_TOO_MANY_OPENED_FILES causes jobs to fail
OneFS 8.0.0.X and Cloudera Impala 5.12.X: Impala queries fail with `WARNINGS: TableLoadingException: Failed to load metadata for table: <tablename> , CAUSED BY: IllegalStateException: null`
Ambari agent fails to send heartbeats to Ambari server if agent is running on a NANON node
NameNode gives out any IP addresses in an access zone, even across pools and subnets; client connection may fail as a result
Other Known Issues
- Host Registrations fails on RHEL 7 hosts with opensslissues
Modify the ambari-agent.ini file:
/etc/ambari-agent/conf/ambari-agent.ini
[security]
force_https_protocol=PROTOCOL_TLSv1_2
Restart the ambari-server and all ambari-agents
https://community.hortonworks.com/questions/145/openssl-error-upon-host-registration.html
OneFS 9.0.0 the services are now disabled by default

Check the service status using isi sevrices -a
hop-ps-a-3# isi services -a
Available Services:
apache2 Apache2 Web Server Enabled
auth Authentication Service Enabled
celog Cluster Event Log Enabled connectemc ConnectEMC Service Disabled
cron System cron Daemon Enabled dell_dcism Dell iDRAC Service Module Enabled dell_powertools Dell PowerTools Agent Daemon Enabled
dmilog DMI log monitor Enabled
gmond Ganglia node monitor Disabled
hdfs HDFS Server Disabled
Enable the hdfs service manually to get going with Hadoop cluster access from hdfs client.