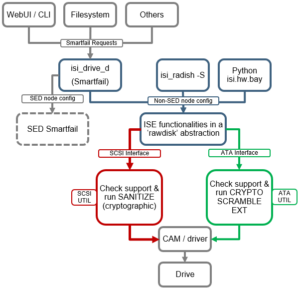
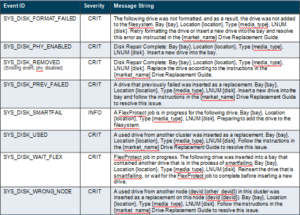
Received several questions from the field recently around OneFS SmartDedupe, so this seemed like a useful topic to delve into. For the first article, we’ll dig into SmartDedupe’s underlying architecture.
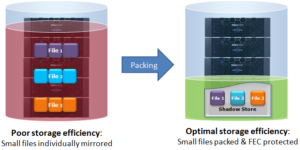
In essence, SmartDedupe helps to maximize the storage efficiency of a cluster by decreasing the amount of physical storage required to house any given dataset. Efficiency is achieved by scanning the on-disk data for identical blocks and then eliminating the duplicates. This approach is commonly referred to as post-process, or asynchronous, deduplication. This is in contrast to the real time, in-line dedupe that’s performed on certain nodes as part of OneFS in-line data reduction. In-line DR will be explored in a future series of blog article. That said…
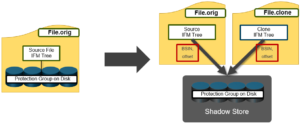
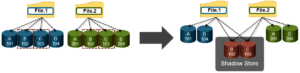
On discovering duplicate blocks, SmartDedupe moves a single copy of those blocks to a special set of files known as shadow stores. During this process, duplicate blocks are removed from the actual files and replaced with pointers to the shadow stores.
With post-process deduplication, new data is first stored on the storage device and then a subsequent process analyzes the data looking for commonality. This means that initial file write or modify performance is not impacted, since no additional computation is required in the write path.
Under the covers, SmartDedupe is comprised of five principle components:
- Deduplication Control Path
- Deduplication Job
- Deduplication Engine
- Shadow Store
- Deduplication Infrastructure
The SmartDedupe job is a highly distributed background process that orchestrates deduplication across all the nodes in the cluster. Job control encompasses file system scanning, detection and sharing of matching data blocks, in concert with the Deduplication Engine.
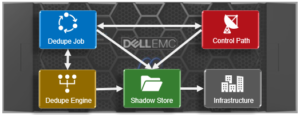
The SmartDedupe control path is the user interface portion, comprising the OneFS WebUI, command line interface and platform API, and is responsible for managing the configuration, scheduling and control of the deduplication job.
SmartDedupe works on data sets which are configured at the directory level, targeting all files and directories under each specified root directory. Multiple directory paths can be specified as part of the overall deduplication job configuration and scheduling. By design, the deduplication job will automatically ignore (not deduplicate) the reserved cluster configuration information located under the /ifs/.ifsvar/ directory, and also any file system snapshots.
It’s worth noting that the RBAC permissions required to configure and modify the deduplication settings are separate from those needed to actually run a deduplication job. For example, a user’s role must have job engine privileges to run a deduplication job. However, in order to configure and modify dedupe configuration settings, they must have the deduplication role privileges.
‘Fingerprinting’ is the part of the dedupe process where unique digital signatures, or fingerprints, are calculated using the SHA-1 hashing algorithm, one for each 8KB data block in the sampled set.
When SmartDedupe runs for the first time, it scans the data set and selectively samples blocks from it, creating the fingerprint index. This index contains a sorted list of the digital fingerprints, or hashes, and their associated blocks. After the index is created, the fingerprints are checked for duplicates. When a match is found, during the sharing phase, a byte-by-byte comparison of the blocks is performed to verify that they are absolutely identical and to ensure there are no hash collisions. Then, if they are determined to be identical, the block’s pointer is updated to the already existing data block and the new, duplicate data block is released.
Hash computation and comparison is only utilized during the sampling phase. For the actual block sharing phase, full data comparison is employed. SmartDedupe also operates on the premise of variable length deduplication, where the block matching window is increased to encompass larger runs of contiguous matching blocks.
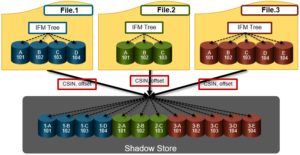
As we saw in the previous article, OneFS shadow stores are file system containers that allow data to be stored in a sharable manner. This allows files to contain both physical data and pointers, or references, to shared blocks in shadow stores.
For example, consider the shadow store information for a regular, undeduped file:
# isi get -DDD file.orig | grep –i shadow * Shadow refs: 0 zero=36 shadow=0 ditto=0 prealloc=0 block=28
A second copy of this file is then created and then deduped:
# isi get -DDD file.* | grep -i shadow * Shadow refs: 28 zero=36 shadow=28 ditto=0 prealloc=0 block=0 * Shadow refs: 28 zero=36 shadow=28 ditto=0 prealloc=0 block=0
As we can see, the block count of the original file has now become zero and the shadow block count for both the original file and it’s and copy has become ‘28′. Additionally, if another file copy is added and deduplicated, the same shadow store info and count is reported for all three files.
It’s worth noting that, even if duplicate file(s) are removed, the original file still retains the shadow store layout.
Dedupe is performed in parallel across the cluster by the OneFS Job Engine via a dedicated deduplication job, which distributes worker threads across all nodes. This distributed work allocation model allows SmartDedupe to scale linearly as an Isilon cluster grows and additional nodes are added.
The control, impact management, monitoring and reporting of the deduplication job is performed by the Job Engine in a similar manner to other storage management and maintenance jobs on the cluster.
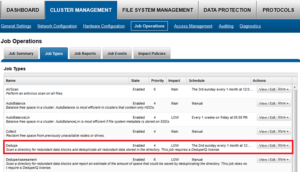
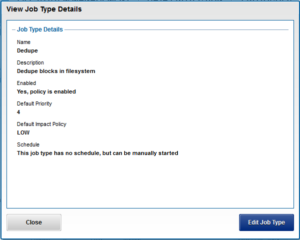
While deduplication can run concurrently with other cluster jobs, only a single instance of the deduplication job, albeit with multiple workers, can run at any one time. Although the overall performance impact on a cluster is relatively small, the deduplication job does consume CPU and memory resources.
Architecturally, the duplication job, and supporting dedupe infrastructure, are made up of the following four phases:
![]()
Because the SmartDedupe job is typically long running, each of the phases are executed for a set time period, performing as much work as possible before yielding to the next phase. When all four phases have been run, the job returns to the first phase and continues from where it left off. Incremental dedupe job progress tracking is available via the OneFS Job Engine reporting infrastructure.
Phase 1 – Sampling
In the sampling phase, SmartDedupe performs a tree-walk of the configured data set in order to collect deduplication candidates for each file. The rational is that a large percentage of shared blocks can be detected with only a smaller sample of data blocks represented in the index table.
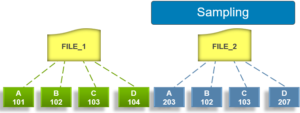
By default, the sampling phase selects one block from every sixteen blocks of a file as a deduplication candidate. For each candidate, a key/value pair consisting of the block’s fingerprint (SHA-1 hash) and file system location (logical inode number and byte offset) is inserted into the index. Once a file has been sampled, the file is flagged and won’t be re-scanned until it has been modified. This drastically improves the performance of subsequent deduplication jobs.
Phase 2 – Duplicate Detection
During the duplicate detection phase, the dedupe job scans the index table for fingerprints (or hashes) that match those of the candidate blocks.

If the index entries of two files match, a request entry is generated. In order to improve deduplication efficiency, a request entry also contains pre and post limit information. This information contains the number of blocks in front of and behind the matching block which the block sharing phase should search for a larger matching data chunk, and typically aligns to a OneFS protection group’s boundaries.
Phase 3 – Block Sharing
For the block sharing phase the deduplication job calls into the shadow store library and dedupe infrastructure to perform the sharing of the blocks.
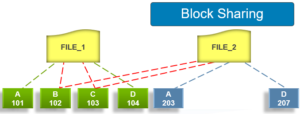
Multiple request entries are consolidated into a single sharing request, which is processed by the block sharing phase, and ultimately results in the deduplication of the common blocks. The file system searches for contiguous matching regions before and after the matching blocks in the sharing request; if any such regions are found, they will also be shared. Blocks are shared by writing the matching data to a common shadow store and creating references from the original files to this shadow store.
Phase 4 – Index Update
The index table is populated with the sampled and matching block information gathered during the previous three phases. After a file has been scanned by the dedupe job, OneFS may not find any matching blocks in other files on the cluster. Once a number of other files have been scanned, if a file continues to not share any blocks with other files on the cluster, OneFS will remove the index entries for that file. This helps prevent OneFS from wasting cluster resources searching for unlikely matches. SmartDedupe scans each file in the specified data set once, after which the file is marked, preventing subsequent dedupe jobs from rescanning the file until it has been modified.