The previous article examined OneFS storage pools, the substrate upon which SmartPools data tiering is built.
Next up the stack are OneFS file pools – the SmartPools logic layer. User configurable file pool policies govern where data is placed, accessed, and protected, accessed, and how it moves among the node pools and tiers.
File pools allow data to be automatically moved from one type of storage to another within a single cluster, to meet performance, space, cost or other criteria – all while retaining its data protection settings, and without any stubs, indirection layers, or other file system modifications.
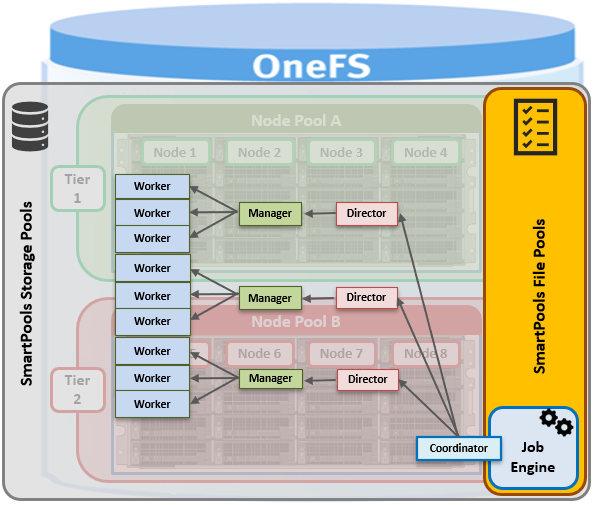
Under the hood, the OneFS job engine is responsible for enacting the file movement, as instructed by configured file pool policies.
In all, there are currently five job engine jobs associated with OneFS SmartPools:
| Job | Description | Default Execution |
| SetProtectPlus | Applies the default file policy. This job is disabled if SmartPools is activated on the cluster | Daily @ 10pm if SP is unlicensed.
Low impact, priority 6 |
| SmartPools | Job that runs and moves data between the tiers of nodes within the same cluster. Also executes the CloudPools functionality if licensed and configured. | Daily @ 10pm
Low impact, priority 6 |
| SmartPoolsTree | Enforces SmartPools file policies on a subtree. | Manual
Medium impact, priority 5 |
| FilePolicy | Efficient changelist-based SmartPools file pool policy job. | Daily @ 10pm
Low impact, priority 6 |
| IndexUpdate | Creates and updates an efficient file system index for FilePolicy job. | Manual
Low impact, priority 5 |
When SmartPools is unlicensed, any disk pool policies are ignored, and instead, the policy is considered to include all disk pools, and file data is directed to, and balanced across, all pools.
When a SmartPools job runs, it examines and compares file attributes against the list of file pool policy rules. To minimize runtime, the initial scanning phase of the SmartPools’ job uses a LIN-based scan, rather than a more expensive tree-walk – and this is typically even more efficient when an SSD metadata acceleration strategy is used.
A SmartPools LIN tree scan breaks up the metadata into ranges for the cluster nodes to work on in parallel. Each node can then dedicate multiple threads to execute the scan on their assigned range. A LIN scan also ensures each file is opened only once, which is much more efficient when compared to a directory walk, where hard links and other constructs can result in single threading, multiple opens, etc.
When a file pool job thread finds a match between a file and a policy, it stops processing additional rules, since that match determines what will happen to the file. Next, SmartPools checks the file’s current settings against those the policy would assign, to identify those which do not match. Once SmartPools has the complete list of settings that it needs to apply to that file, it sets them all simultaneously, and moves to restripe that file to reflect any and all changes to node pool, protection, SmartCache use, layout, etc.
The file pool policy engine falls under the control and management of the SmartPools job. The default schedule for this process is every day at 10pm, and with a low impact policy. However, this schedule, priority and impact can be manually configured and tailored to a particular environment and workload.
SmartPools can also be run on-demand, to apply the appropriate file-pool membership settings to an individual file, or subdirectory, without having to wait for the background scan to do it.
For example, to test what affect a new policy will have, the ‘isi filepool apply’ command line utility can be run against a small subset of the data, which can be either a single file, or group of files or directories. This CLI command can either be run live, to actually make the policy changes, or in a ‘dry-run’ assessment mode, using the ‘-nv’ flags, to estimate the scope and effect of a policy.
For a detailed view of where a SmartPools-managed file is at any time, the ‘isi get’ CLI command can provide both the actual node pool location, and the file pool policy-dictated location – or where that file will move to, after the next successful SmartPools job run.
When data is written to the cluster, SmartPools writes it to a single node pool only. This means that, in almost all cases, a file exists in its entirety within a node pool, and not across pools
Unlike the SmartPools job, which scans the entire LIN tree, and the SmartPoolsTree job which visits a subtree of files, the FilePolicy job, introduced in OneFS 8.2, provides a faster, lower impact method for applying file pool policies. In conjunction with the IndexUpdate job, FilePolicy improves job scan performance, by using a snapshot delta based ‘file system index’, or changelist, to find files needing policy changes.
Avoiding a full treewalk dramatically decreases the amount of locking and metadata scanning work the job is required to perform, improving execution time, and reducing impact on CPU and disk – albeit at the expense of not quite doing everything that SmartPools does. However, most of the time SmartPools and FilePolicy perform the same work. Disabled by default, FilePolicy supports a wide range of file policy features, reports the same information, and provides the same configuration options as the SmartPools job. Since FilePolicy is a changelist-based job, it performs best when run frequently – once or multiple times a day, depending on the configured file pool policies, data size and rate of change.
When enabling and using the FilePolicy and IndexUpdate jobs, the recommendation is to continue running the SmartPools job as well, but at a much-reduced frequency.
FilePolicy requires access to a current index. This means that if the IndexUpdate job has not yet been run, attempting to start the FilePolicy job will fail with an error message, prompting to run the IndexUpdate job first. And once the index has been created, the FilePolicy job will run as expected. The IndexUpdate job can be run several times daily (for example. every six hours) to keep the index current and prevent the snapshots it uses from growing large.
User configurable file pool policies govern where data is placed, accessed, and protected, accessed, and how it moves among the node pools and tiers. As such, these policies can be used to manage three fundamental properties of data storage:
| Property | Description |
| Location | The physical tier or node pool in which a file lives. |
| Performance | A file’s performance profile, or I/O optimization setting, which includes sequential, concurrent, or random access. Plus SmartCache write caching |
| Protection | The protection level of a file, and whether it’s FEC parity-protected or mirrored. |
For example, a file pool policy may dictate that anything written to path /ifs/foo goes to the H-Series nodes in node pool 1, then moves to the A-Series nodes in node pool 3 when older than 30 days. The file system itself is doing the work, so there are no transparency or data access risks to worry about.
Also, to simplify management, there are defaults in place for node pool and file pool settings which handle basic data placement, movement, protection and performance. There are several generic template policies, too, which can be customized, cloned, or used as-is
Data movement is parallelized, with the resources of multiple nodes combining for efficient job completion. While a SmartPools job is running and tiering is in progress, all data is completely available to users and applications.
The performance of node pools can also be governed with SmartPools SSD ‘Strategies’, which can be configured for read caching or metadata storage. Plus the overall system performance impact can be tuned to suit the peaks and lulls of an environment’s workload, by scheduling the SmartPools job to run during off-peak hours.