In this second article in the series, we’ll take an in-depth look at MetadataIQ’s architecture and operation.
The OneFS MetadataIQ framework is based on the following core components:

A ‘MetadataIQ cycle’ describes the complete series of steps run by the MetadataIQ service daemons, which represent the full sequence, from determining the changes between two snapshots through updating the ElasticSearch database.
On the cluster side there are three core MetadataIQ components that are added in OneFS 9.10: The Producer Service, Consumer Service, and Transfer agent.
The producer service daemon, isi_metadataiq_producer_d, is responsible for running a metadata scan of the specified OneFS file system path, according to a configured schedule.
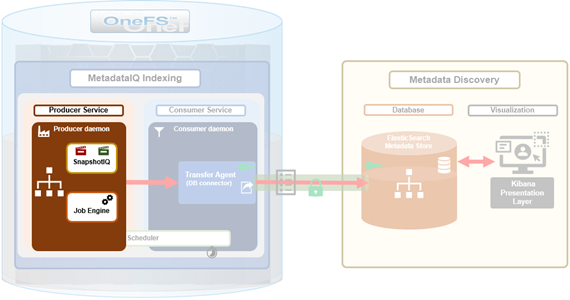
When first started, or in response to a configuration change, the producer daemon first loads its configuration, which instructs it on parameters such as the file system path to use, what schedule to run on, etc. Once the producer has found a valid schedule configuration string, it will start its first execution process, or ‘producer cycle’, performing the following actions:
- A new snapshot of the configured file system path is taken.
- Next, a ChangelistCreate job is started between the previous snapshot and the newly-taken snapshot checkpoints.
- This ChangelistCreate job instance is monitored and, if necessary, restarted per a configurable number of retry attempts.
- A consumer checkpoint file (CCP) is generated.
- Finally, cleanup is performed and the old snapshot removed.
It’s worth noting that, in this initial version of MetadataIQ, only a single path may be configured.
Internally, the consumer checkpoint (CCP) is a JSON file containing a system b-tree created by the ChangelistCreate job, providing a delta between two input snapshots. These CCP files are created under the /ifs/.ifsvar/modules/metadataiq/cp/ directory with a ‘Checkpoint’ nomenclature followed by an incrementing ID. For example:
# ls /ifs/.ifsvar/modules/metadataiq/cp/ Checkpoint_0_2.json
To aid identification, the producer daemon creates its snapshots with a naming convention that includes both a ‘MetadataIQ’ prefix and creation timestamp naming convention for easy identification, plus an expiration value of one year. For example:
# isi snapshot snapshots list | grep -i metadata 3278 MetadataIQ_1730914225 /ifs/data
During a producer cycle, once a CCP file is successfully generated, the old snapshot from the on-going cycle gets cleaned up. This snapshot deletion actually occurs in two phases: While the producer daemon initiates snapshot removal, the actual deletion is performed by the Job Engine’s SnapshotDelete job. As such, the contents of a ‘deleted’ snapshot may still exist until a SnapshotDelete job has run to completion and actually cleaned it up.
If a prior MetadataIQ execution cycle has not already completed, the old snapshot ID will automatically be set to HEAD (i.e.ID=0), and only the new snapshot will be used to report the current metadata state under the configured path.
Next, the MetadataIQ consumer service takes over the operations.

The consumer service relies on a set of database configuration parameters, including the CA certificate attributes, in order to securely connect to the remote ElasticSearch instance. These include:

Note that, in OneFS 9.10, MetadataIQ only supports the ElasticSearch database as its off-cluster metadata store.
Additionally, the consumer daemon, isi_metadataiq_consumer_d, also has a couple of configurable parameters to control and tune its behavior. There are:

The consumer daemon checks the queue for the arrival of a new checkpoint (CCP) file. When a CCP arrives, the daemon instructs the transfer agent to upload the metadata to the Elasticsearch database. The consumer daemon also continuously monitors the successful execution of the transfer agent, restarting it if needed.
If there happens to be more than one CCP in the queue, the consumer daemon will always select the file with the oldest timestamp.
The actual mechanics of uploading the consumer checkpoint (CCP) file to the remote database are handled by the transfer agent.
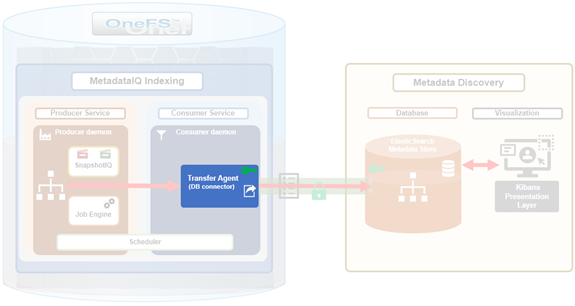
The transfer agent (isi_metadataiq_transfer), a python script, which is spawned on demand by the consumer daemon.
- The transfer script is invoked with the path to a CCP file specifying the target changelist.
- Next, the transfer script attempts to take an advisory lock on the CCP file to prevent more than one instance of the transfer script working on the same CCP file at a given time. This advisory lock is released whenever the transfer script completes or terminates.
- After acquiring the advisory lock, the transfer script validates that both the CCP file and changelist exist, and that the ElasticSearch database connection and mapping are valid. It will configure the index mappings if the index does not already exist.
- If everything is fine in the above step, the transfer script will start its ‘draining loop’, fetching and batching changelist entries and allocating them to a worker thread pool for data processing and transfer.
- Once the changelist is fully transferred to the ElasticSearch database, the transfer script removes the CCP file and changelist.
- Finally, the transfer script releases its advisory lock and exits normally.
In the event of a failure, the transfer agent is automatically restarted by the consumer daemon.
After the initial cluster setup and config, each additional MetadataIQ job run populates the remote ElasticSearch database with updated metadata from the configured dataset.
The ElasticSearch database and Kibana visualization portal reside on an off-cluster Linux host.
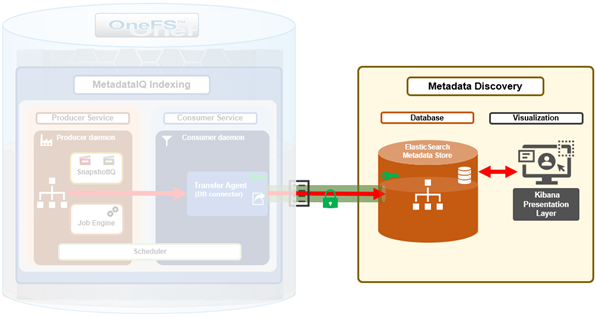
ElasticSearch typically uses TCP port 9200 by default, for communication and receiving metadata updates from the PowerScale cluster(s). Kibana typically runs by default on TCP port 5601.
Periodic synchronizations are needed to keep the database updated with new metadata changes, and the recommendation is to configure a dataset-appropriate schedule for the MetadataIQ job. And with the services enabled, the first MetadataIQ cycle begins as soon as a valid schedule has been configured.
In the next article in this series, we’ll examine the process involved in standing up and configuring a MetadataIQ environment.