Prominent amongst the payload of the new OneFS 9.10 release is MetadataIQ – PowerScale’s new global metadata namespace solution.

Incorporating the ElasticSearch database and Kibana visualization dashboard, MetadataIQ facilitates data indexing and querying across multiple geo-distributed clusters.
OneFS MetadataIQ is purpose-built to provide robust metadata capabilities, allowing customers to index and discover the data they need for their workflows during file creation and modification, negating the need for time-consuming treewalks . The metadata catalog may be used for queries, data visualization, and data lifecycle management. As customers add analytics workflows, the ability to simply and efficiently query data, wherever it may reside, is vital for the time-to-results they require.
The MetadataIQ framework is used to transfer file system metadata from a cluster to an external ElasticSearch database instance. Internally, MetadataIQ leverages the venerable OneFS Job Engine’s ChangeListCreate job, which tracks the delta, or changelist, between two snapshots. MetadataIQ parses entries in each changelist in batches, updating the metadata index residing off-cluster in an ElasticSearch database. This database can store the metadata from multiple PowerScale clusters, providing a global catalog of an organization’s unstructured data repositories.
The exported OneFS file system metadata contains the fields and attributes which are typically reported by the ubiquitous ‘stat’ CLI command, including:
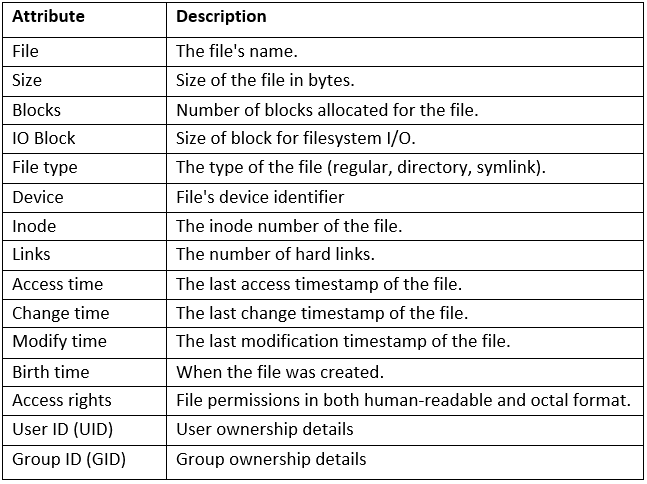
In addition to these standard metadata attributes, MetadataIQ also includes a number of cluster-specific fields, including path, LINs and parent LINs, disk and nodepool membership, associated snapshots, etc. The full schema, including the metadata categories, fields, types, and descriptions, will be presented in a future blog article in this series.
Behind the scenes, OneFS MetadataIQ comprises the following principal components:

The high level architecture of the MetadataIQ framework is as follows:
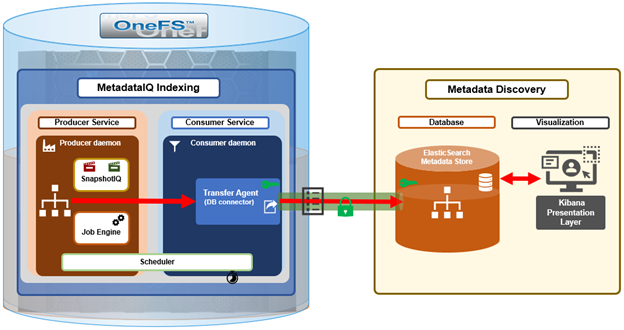
A ‘MetadataIQ cycle’ is the complete series of steps run by the MetadataIQ daemons, which represent a full sequence of analyzing the changes between two snapshots and updating the ElasticSearch database.
On the cluster side there are three core MetadataIQ components that are added in OneFS 9.10: The Producer Service, which coordinates snapshot generation and changelist job execution, according to a specified schedule, generating a consumer checkpoint file. The Consumer Service, which detects new checkpoint files and manages and monitors the database connectivity. And the Transfer agent, which, under the purview of the Consumer, actually performs the metadata uploads to the remote ElasticSearch instance.
Off-cluster, a Linux server running the Docker container service hosts the ‘ELK’ stack. This includes the ElasticSearch database that houses the metadata index, paired with the Kibana dashboard, which provides the query and data visualization engine.
After the initial cluster setup and config, each additional MetadataIQ job run populates the remote ElasticSearch database with updated metadata from the configured dataset. Periodic synchronizations are needed to keep the database updated with new metadata changes, and the recommendation is to configure a dataset-appropriate schedule for the MetadataIQ job. And with the services enabled, the first MetadataIQ cycle will start as soon as a valid schedule has been configured.
From the Kibana UI, the ‘Discover’ page notifies of a new data source once MetadataIQ has been successfully configured and run on the cluster. After this, creating a data view is a simple as selecting the desired index and clicking the ‘Save data view to Kibana’ button. Once done, Kibana’s ‘Discover’ mode allows you to craft and run data queries by creating one or more filters to display a desired subset of metadata entries. Moving from ‘Discover’ mode to ‘Dashboard’ allows rich custom visualizations to be created. Kibana provides multiple data presentation options, such as a bar chart, here representing ‘file and physical size distributions’ data.

Or a pie chart, here displaying metadata from multiple clusters.

Up-leveled data can be collated and represented in the dashboard as interactive charts, and clicking or hovering over the desired region allows you to easily access the details.
So there you have it – the new OneFS MetadataIQ, providing smart, efficient, and scalable metadata querying and management across a federated PowerScale metadata index. Plus, in addition to streamlining data access and boosting operation efficiency, MetadataIQ can also facilitate AI workflows such as intelligent chunking and retrieval-augmented generation (RAG).
In the next article in this series, we’ll take an in-depth look at MetadataIQ’s architecture and operation.