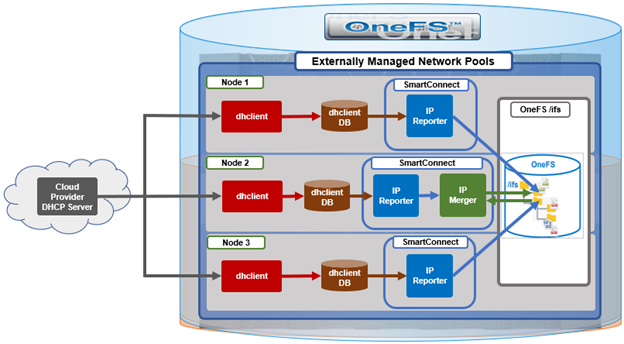
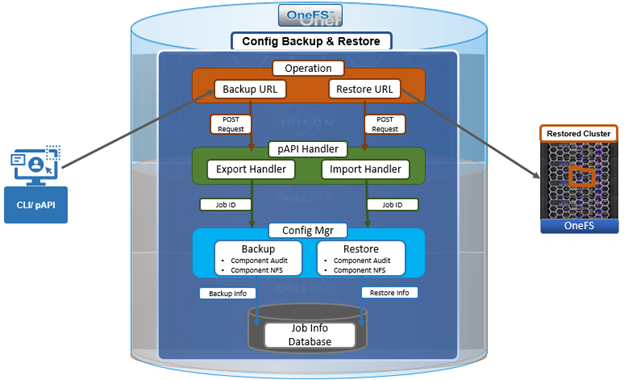
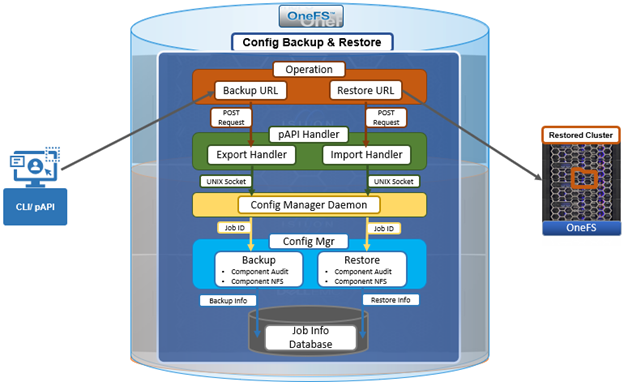
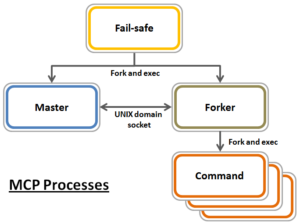
In the first article in this series, we took a look at the overview and architecture of the OneFS 9.7 externally managed network pools feature. Now, we’ll turn our focus to its management and monitoring.
From a cluster security point of view, the externally managed IP service has opened up a potential new attack vector whereby a rogue DHCP server could provide bad data. As such, the recommendation is to configure a firewall around this new OneFS DHCP service to ensure that the cluster is protected. While the OneFS firewall could in theory provide this protection, in order to know what the DHCP server is, the cluster first has to discover and talk to the DHCP server and get its IP. This seems a bit paradoxical (and insecure) to be creating a firewall rule after having already talked to and trusted the DHCP server.
The following table contains recommended configuration settings for the AWS firewall.
| Setting | Value |
| Name | Eg. ‘DHCP” |
| Type | ‘ingress’ |
| From Port | 67 |
| To Port | 68 |
| Protocol | UDP |
| CIDR Blocks | <cluster_gateway>/32 |
| IPv6 CIDR Blocks | [] |
| Security Group ID | // customer specific |
Note that, as mentioned in the first article in this series, there are a currently a couple of instances of unsupported networking functionality in the APEX file services for AWS offering, as compared to on-prem OneFS, and these include:
- IPv6 support
- VLANs
- Link aggregation
- NFSoverRDMA
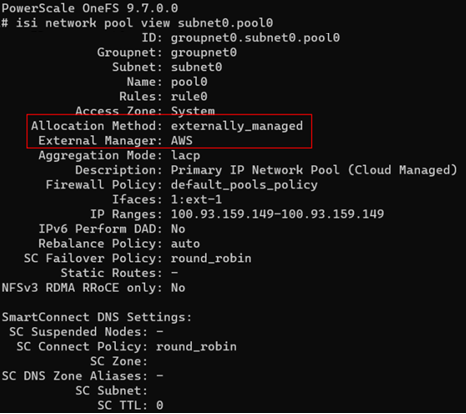
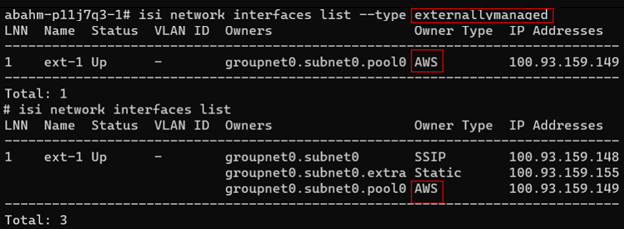
These limitations for externally managed network pools are highlighted in red below, and are read-only settings since they are managed by the cloud provider (interfaces and IPs).
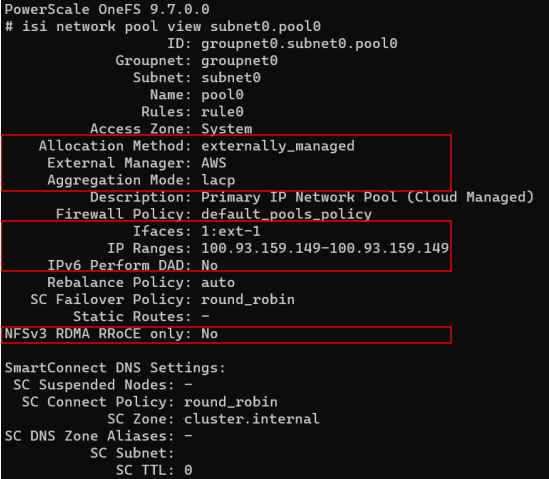
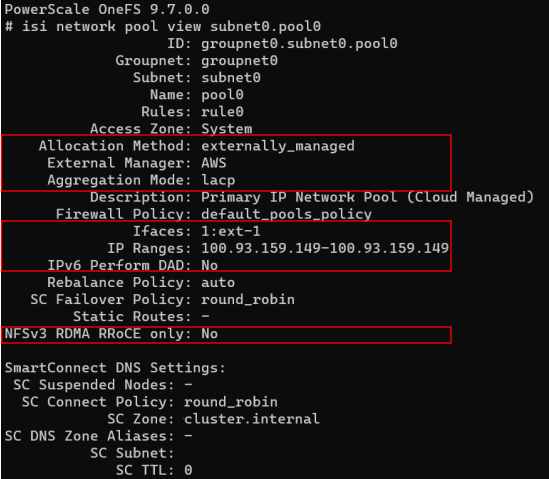
Externally managed network pools can only be created by the system with OneFS 9.7 and therefore pools cannot be manually reconfigured either to or from externally managed – even by root.
In general manual IP configuration is protected in order to guard against accidental misconfiguration. However, clusters admin may occasionally be required to manually configure the IPs in the network pool, and can be performed with the ‘isi network pool modify’ plus the inclusion of the ‘–force’ flag:
# isi network pool modify subnet0.pool0 –ranges <ip_add_range> --force
Note that AWS has a maximum threshold for the number of IPs that can be configured per network interface based on AMI instance type. If this limit is exceeded, AWS will prevent the IP address from being configured, resulting in a potential data unavailability event. OneFS 9.7 now prevents most instances of IP oversubscription at configuration time in order to ensure availability during a 1/3 cluster outage.
While OneFS accounts for externally managed, static, dynamic IPs, and SSIPs, it is unable to account for unevenly allocated dynamic IPs, so it’s therefore unable to prevent all instances.
OneFS also displays an informative error message if attempting to configure this. For example, using an AMI instance type of ‘m5d.large’:
# isi network pool modify subnet0.pool0 –ranges 10.20.30.203-10.20.30.254
AWS only allows node 2 (instance type AWS=m5d.large) to have a maximum of 10 IPv4 addresses configured. In a degraded state, the requested configuration will result in node 2 attempting to configure 28 addresses, which will leave 18 address(es) unavailable. To resolve this, consider increasing the number of nodes in dynamic pools or reducing the number of IPv4 addresses.
When it comes to troubleshooting externally managed pools, there are two log files which are useful to check. Namely:
- /var/log/dhclient.log
- /var/log/isi_smartconnect
The first of these is a dedicated dhclient.log file for the new dhclient instance that OneFS 9.7 introduces. In contrast, the IP Merger and IP Reporter modules will output to the isi_smartconnect log.
There are also a handful of relevant system files that are also worth being aware of, and these include:
- /var/db/dhclient/lease.ena1
- /ifs/.ifsvar/modules/flexnet/ip_reporter/DHCP/node.
- /ifs/.ifsvar/modules/flexnet/pool_members/groupnet.1.subnet.1.pool.1
- /ifs/.ifsvar/modules/smartconnect/resource/workers/ip_merger
The first of these, lease.ena1, is an append log maintained by dhclient. So the most recent lease in there is the one that is SmartConnect is looking at. Note that there may be other lease files in the system, but only the lease files in /var/db/dhclient are relevant, and being viewed by SmartConnect. OneFS has a special configuration for dhclient to ensure this.
The IP reports live in the /ifs/.ifsvar/modules/flexnet directory. The pool_members directory has been present in OneFS for a number of years now. And OneFS now coordinates the IP merger with the file under ./smartconnect/resource/workers/ directory.
As for useful CLI commands, these include the following:
# isi_smartconnect_client action –a wake-ip-reporter
The ‘isi_smartconnect_client’ CLI utility, which can be used to interact with the SmartConnect daemon, gets an additional ‘wake-ip-reporter’ action in OneFS 9.7. Under normal circumstances, the IP Reporter only checks the contents of the lease file every five minutes. However, ‘wake-ip-reporter’ now instructs IP Reporter to check the lease file immediately. So if there was some issue where dhclient restarted for some reason, IP Reporter can be awoken and forced to read the lease, rather than waiting for its next scheduled check.
Additionally, the following ‘log_level’ command arguments can be used to change the logging level of SmartConnect to the desired verbosity:
# isi_smartconnect_client log_level [-l | -r]
Note that, in OneFS 9.7, this does not change the Flexnet config file which was required in prior releases.
Instead, this log level is reset when the process dies or the ‘–r’ argument is passed. It’s worth noting that this command does not operate cluster-wise. Rather, it just affects the current instance of SmartConnect running on the local node.
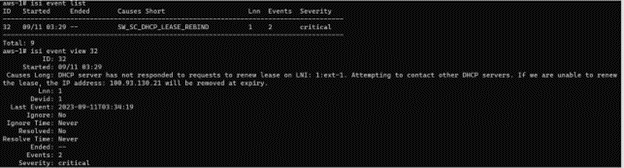
Another thing to be aware of when a cluster is using externally managed pools is that networking is dependent on, and can be impacted by, the availability of AWS’ DHCP servers. While the leased IP never changes, the leases themselves have an expiration of an hour. As such, if OneFS is unable to reach the DHCP server to renew, it may lose its Primary IPs. While this is often outside the realm of control, the OneFS CELOG event service will fire a critical warning alert (SW_SC_DHCP_LEASE_REBIND) before a primary IP expires. This alert will contain the following event description:
DHCP server has not responded to requests to renew lease on <interface>. Attempting to contact other DHCP servers. If we are unable to renew the lease, the IP address <ip_address> will be removed at expiry.
For example:
In addition to the above alert, there are several log messages that give a good indication of what may be amiss. These, and their resolution info, are summarized in the following table:
| Log Message | Description | Resolution |
| Unable to merge IP 1.2.3.4 on ext-1 from devid 1 – no matching pool found | IP is not configured in any Network Pool | Add IP to the Primary IP Pool |
| Unable to parse lease on NIC: ena1. Attempting to retrieve new lease | The lease file generated by dhclient could not be read. | None should be required. We will automatically backup the old lease file and restart dhclient |
| Lease on NIC: ena1 not found | Lease file does not exist for the specified interface | OneFS will automatically restart dhclient |
| Unexpected error comparing IP Reports. Attempting rewrite | We try to dedupe writes by comparing newly generated IP report with what is on disk. In the event of a failure, we’ll just overwrite. | |
| No IP Report received from DHCP External Manager | OneFS unable to determine its IP from the DHCP leases. Will continue retrying, but currently unable to report an IP | If issues persists, check on dhclient to ensure it is operating correctly. |
| Failed to write IP Report node. for DHCP to disk: | OneFS unable to report its IP to /ifs, so the IP merger is unable to update Flexnet/IP Assignments with this information. | Check why SmartConnect is unable to write to /ifs. Is it read only? |