Dell PowerScale is already scaling up the holiday season with the launch of the innovative OneFS 9.10 release, which shipped today (10th December 2024). This new 9.10 offering is an all-rounder, introducing PowerScale innovations in capacity, performance, security, serviceability, data management, and general ease of use.

OneFS 9.10 delivers the next version of PowerScale’s common software platform for both on-prem and cloud deployments. This can make it a solid fit for traditional file shares and home directories, vertical workloads like M&E, healthcare, life sciences, financial services, and next-gen AI, ML and analytics applications.
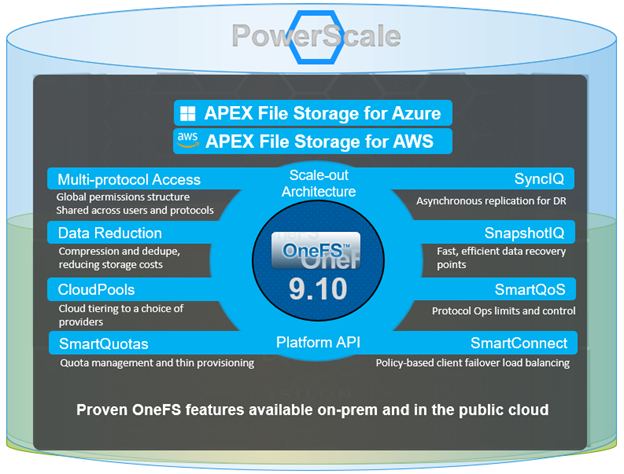
PowerScale’s clustered scale-out architecture can be deployed on-site, in co-lo facilities, or as customer managed Amazon AWS and Microsoft Azure deployments, providing core to edge to cloud flexibility, plus the scale and performance and needed to run a variety of unstructured workflows on-prem or in the public cloud.
With data security, detection, and monitoring being top of mind in this era of unprecedented cyber threats, OneFS 9.10 brings an array of new features and functionality to keep your unstructured data and workloads more available, manageable, and secure than ever.
Hardware Innovation
On the platform hardware front, OneFS 9.10 unlocks dramatic capacity and performance and enhancements – particularly for the all-flash F910 node, which sees the introduction of support for 61TB QLC SSDs, plus 200Gb Ethernet front and backend networking.
Additionally, the H and A-series chassis-based hybrid platforms also see a significant density and per-watt efficiency improvement with the introduction of 24TB HDDs. This includes both ICE and FIPS drives, accommodating both regular and SED clusters.
Networking and performance
For successful large-scale AI model customization and training and other HPC workloads, compute farms need data served to them quickly and efficiently. To achieve this, compute and storage must be sized and deployed accordingly to eliminate potential bottlenecks in the infrastructure.
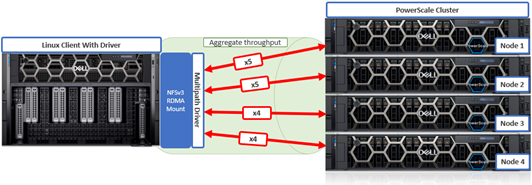
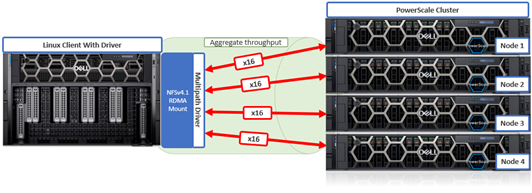
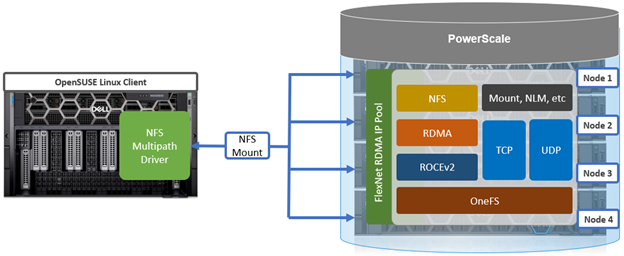
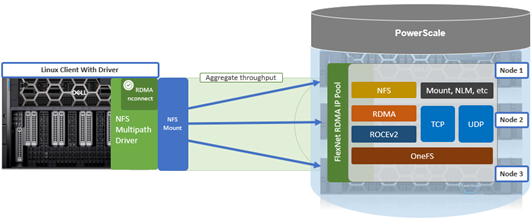
To meet this demand, OneFS 9.10 introduces support for low latency front-end and back-end HDR Infiniband network connectivity on the F710 and F910 all-flash platform, providing up to 200Gb/s of bandwidth with sub-microsecond latency. This can directly benefit generative AI and machine learning environments, plus other workloads involving highly concurrent streaming reads and writes of different files from individual, high throughput capable Linux servers. In conjunction with the OneFS multipath driver, and GPUdirect support, the choice of either HDR Infiniband or 200GbE can satisfy the networking and data requirements of demanding technical workloads such as ADAS model training, seismic analysis, and complex transformer-based AI workloads, deep learning systems, and trillion-parameter generative AI models.
Metadata Indexing
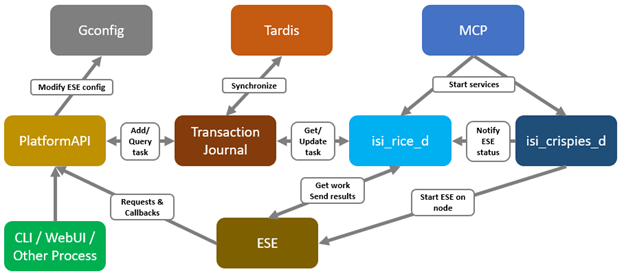
Also debuting in OneFS 9.10 is MetadataIQ, a new global metadata namespace solution. Incorporating the ElasticSearch database and Kibana visualization dashboard, MetadataIQ facilitates data indexing and querying across multiple geo-distributed clusters.
MetadataIQ efficiently transfers file system metadata from a cluster to an external ELK instance, allowing customers to index and discover the data they need for their workflows and analytics needs. This metadata catalog may be used for queries, data visualization, and data lifecycle management. As workflows are added, MetadataIQ simply and efficiently queries data, wherever it may reside, delivering vital time-to-results.
Internally, MetadataIQ leverages the venerable OneFS ChangeListCreate job, which tracks the delta between two snapshots, batch processing and updating the off-cluster metadata index residing in an ElasticSearch database. This index can store metadata from multiple PowerScale clusters, providing a global catalog of an organization’s unstructured data repositories.
Security
In OneFS 9.10, OpenSSL is upgraded from version 1.0.2 to version 3.0.14. This makes use of the newly validated OpenSSL 3 FIPS module, which all of the OneFS daemons make use of. But probably the most significant feature in the OpenSSL 3 upgrade is the addition of library support for the TLS 1.3 ciphers, designed to meet stringent Federal requirements. OneFS 9.10 adds TLS 1.3 support for the WebUI and KMIP key management servers, and verifies that 1.3 is supported for LDAP, CELOG alerts, audit events, syslog forwarding, SSO, and SyncIQ.
Support and Monitoring
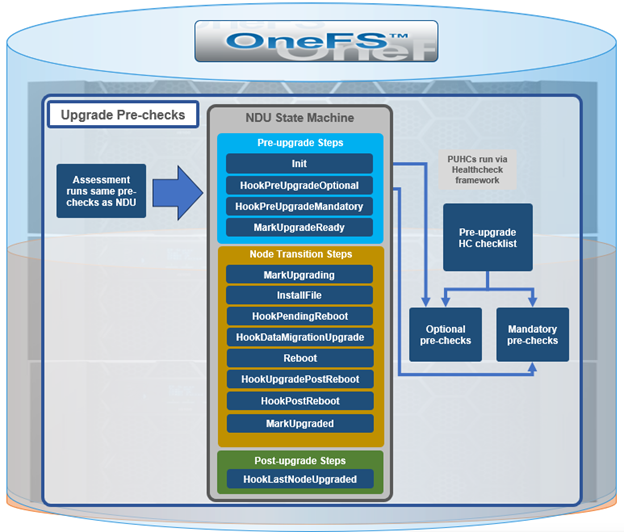
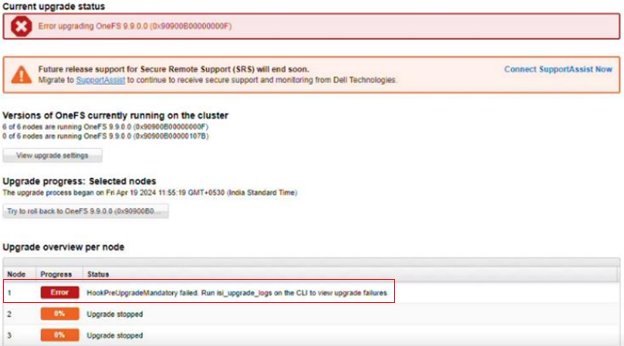
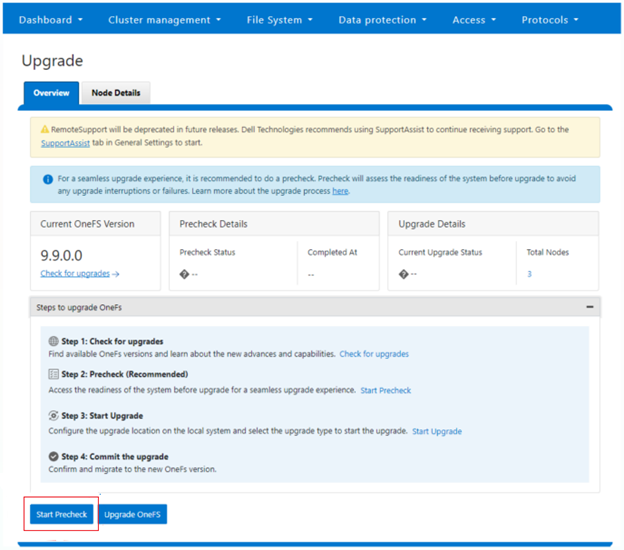
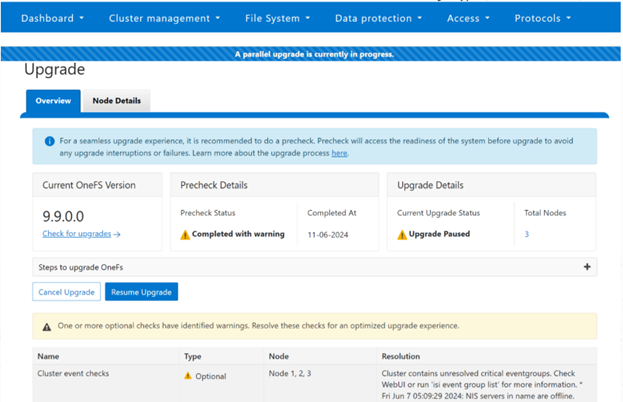
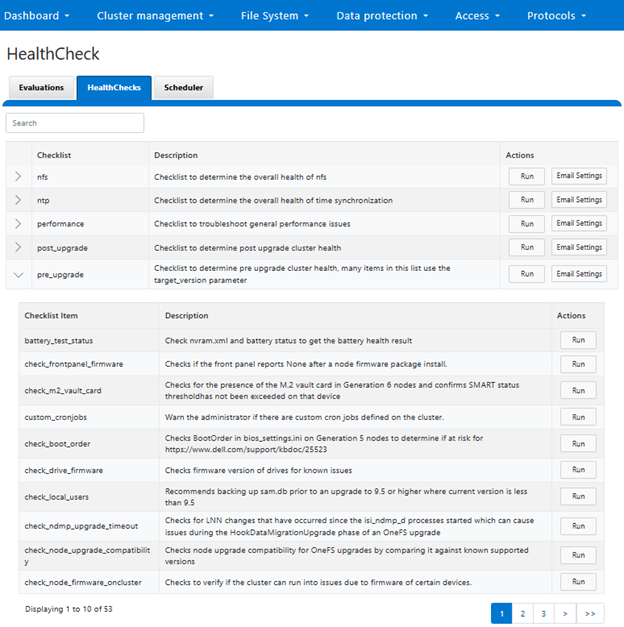
OneFS 9.10 also includes healthcheck enhancements to aid the customer in understanding cluster state and providing resolution guidance in case of failures. In particular, current healthcheck results are displayed in the WebUI landing page to indicate the real-time health of the system. Also included is detailed failure information, troubleshooting steps, and resolution guidance – including links to pertinent knowledge base articles. Healthchecks are also logically grouped based on category and frequency, and historical checks are also easily accessible.
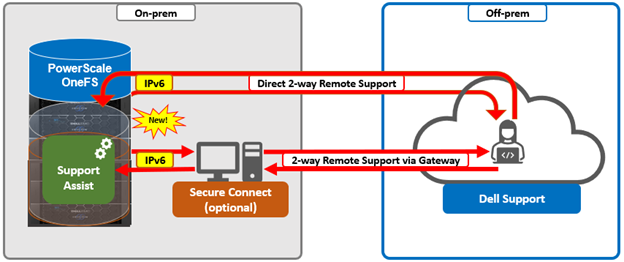
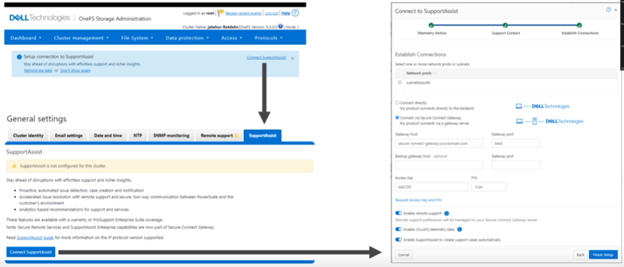
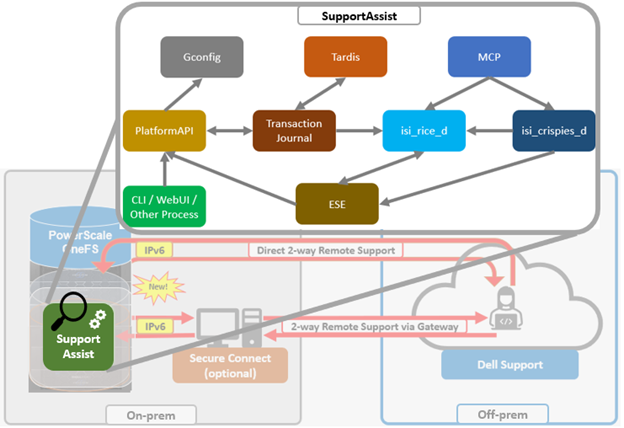
Dell Technologies Connectivity Services also replaces the former SupportAssist in OneFS 9.10, with the associated updating of user-facing Web and command line interfaces. Intended for transmitting events, logs, and telemetry from PowerScale to Dell support, Dell Technologies Connectivity Services provides a full replacement for SupportAssist. With predictive issue detection and proactive remediation, Dell Technologies Connectivity Services helps rapidly identify, diagnose, and resolve cluster issues, improving productivity by replacing manual routines with automated support. Delivering a consistent remote support experience across the Dell storage portfolio, Dell Technologies Connectivity Services is intended for all sites that can send telemetry off-cluster to Dell over the internet, and is included with all support plans (features vary based on service level agreement).
In summary, OneFS 9.10 brings the following new features and functionality to the Dell PowerScale ecosystem:
| OneFS 9.10 Feature | Description |
| Networking | · Front-end and back-end HDR Infiniband networking option for the F910 and F710 platforms. |
| Platform | · Support for F910 nodes with 61TB QLC SSD drives and a 200Gb/s back-end Ethernet network.
· Support for 24TB HDDs on A-series and H-series nodes. |
| Metadata Indexing | · Introduction of MetadataIQ off-cluster metadata indexing and discovery solution. |
| Security | · OpenSSL 3.0 and TLS 1.3 transport layer security support. |
| Support and Monitoring | · Healthcheck WebUI enhancements
· Dell Technologies Connectivity |
We’ll be taking a deeper look at OneFS 9.10’s new features and functionality in future blog articles over the course of the next few weeks.
Meanwhile, the new OneFS 9.10 code is available on the Dell Support site, as both an upgrade and reimage file, allowing both installation and upgrade of this new release.
For existing clusters running a prior OneFS release, the recommendation is to open a Service Request with to schedule an upgrade. To provide a consistent and positive upgrade experience, Dell EMC is offering assisted upgrades to OneFS 9.10 at no cost to customers with a valid support contract. Please refer to Knowledge Base article KB544296 for additional information on how to initiate the upgrade process.