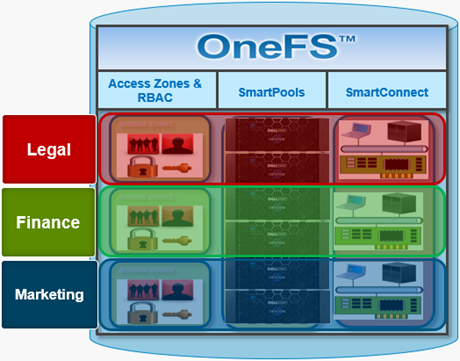
Multi-tenancy in OneFS is predicated upon the following four areas:
| Area | Feature | Description |
| Security | Access Zones | Share and export-level access control departmental segregation |
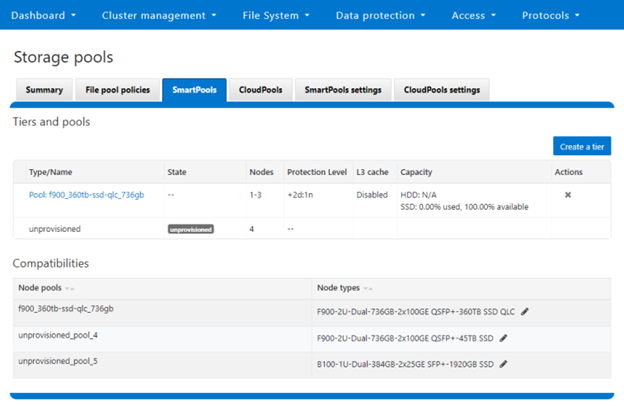
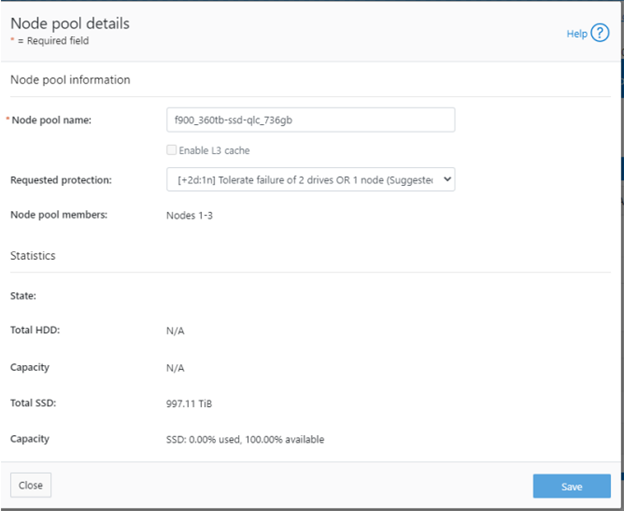
| Data | SmartPools | Nodepools and Tiers for data segregation |
| Networking | SmartConnect | Groupnets and Zones for network segmentation |
| Administration | RBAC | Data access and administration separation |
For authentication and access control, OneFS Access Zones provide a way to associate the cluster with multiple sets of auth providers to provide varied access to cluster resources. Each zone contains the necessary configuration to support authentication and identity management services for client access to OneFS.
A combination of SmartConnect zones, node pools, and access zones enables the separation of authentication providers into different groups and provides a mechanism to limit data access to specific node groups, network interfaces, directory hierarchies and file system areas. The following image shows three ‘tenants’ (in this case business units in an enterprise), each with their own subset of cluster resources – network pool, node pool, and authentication & identity management infrastructure.
Within OneFS, Role-based access control (RBAC) provides the ability to grant cluster administrators the necessary privileges to perform various tasks through the Platform API, such as creating/modifying/viewing NFS exports, SMB shares, authentication providers, and various cluster settings. For example, data center operations staff can be assigned read-only rights to the entire cluster, allowing full monitoring access but no configuration changes to be made. OneFS provides a collection of built-in roles, including audit, system & security administrator, plus the ability to create custom defined roles, either per access zone or across the cluster. Roles Based Administration is integrated with the OneFS command line interface, WebUI and Platform API.
OneFS RBAC enables roles and a subset of zone-aware privileges to be assigned on a per-access-zone basis. This allows administrative tasks covered by the zone-aware privileges to be permitted inside a specific access zone, by defining a ‘local administrator’ for that zone. A user in the System access zone still has the ability to administer all other access zones, and so remains a ‘global administrator’. However, a user in a non-System access zone can also be given a set or privileges to act as a ‘local administrator’ for that particular zone, as well as being able to view (but not modify) global settings related to those privileges.
The following privileges are available in non-System access zones:
| Privilege | Description |
| ISI_PRIV_LOGIN_PAPI | Log in to Platform API and WebUI |
| ISI_PRIV_AUTH | Configure identities, roles and authentication providers |
| ISI_PRIV_AUTH_GROUPS | User groups from authentication provider |
| ISI_PRIV_AUTH_PROVIDERS | Configure Auth providers |
| ISI_PRIV_AUTH_RULES | User mapping rules. |
| ISI_PRIV_AUTH_SETTINGS_ACLS | Configure ACL policy settings |
| ISI_PRIV_AUTH_SETTINGS_GLOBAL | Configure global authentication settings |
| ISI_PRIV_AUTH_USERS | Users from authentication providers |
| ISI_PRIV_AUTH_ZONES | Configure access zones |
| ISI_PRIV_RESTRICTED_AUTH | Configure identities with the same or lesser privilege |
| ISI_PRIV_RESTRICTED_AUTH_GROUPS | Configure identities with the same or lesser privilege |
| ISI_PRIV_RESTRICTED_AUTH_USERS | Configure identities with the same or lesser privilege |
| ISI_PRIV_ROLE | Create new roles and assign privileges |
| ISI_PRIV_AUDIT | Configure audit capabilities |
| ISI_PRIV_FILE_FILTER | Configure File Filtering based on file types |
| ISI_PRIV_FILE_FILTER_SETTINGS | File Filtering service and filter settings |
| ISI_PRIV_HDFS | Setup HDFS Filesystem, service, users and settings |
| ISI_PRIV_HDFS_FSIMAGE_JOB_SETTINGS | HDFS FSImage job settings |
| ISI_PRIV_HDFS_FSIMAGE_SETTINGS | HDFS FSImage service settings |
| ISI_PRIV_HDFS_INOTIFY_SETTINGS | HDFS Inotify service settings |
| ISI_PRIV_HDFS_PROXYUSERS | Proxy users and members |
| ISI_PRIV_HDFS_RACKS | HDFS virtual rack settings |
| ISI_PRIV_HDFS_RANGERPLUGIN_SETTINGS | Settings for the HDFS ranger plugin |
| ISI_PRIV_HDFS_SETTINGS | HDFS Service, protocol and ambari server settings |
| ISI_PRIV_NFS | Setup NFS Service, exports and configure settings |
| ISI_PRIV_NFS_ALIASES | Aliases for export directory names |
| ISI_PRIV_NFS_EXPORTS | NFS Exports and permissions |
| ISI_PRIV_NFS_SETTINGS | NFS export and other settings |
| ISI_PRIV_NFS_SETTINGS_EXPORT | NFS export and user mapping settings |
| ISI_PRIV_NFS_SETTINGS_GLOBAL | NFS global and service settings |
| ISI_PRIV_NFS_SETTINGS_ZONE | NFS zone related settings |
| ISI_PRIV_PAPI_CONFIG | Configure the Platform API and WebUI |
| ISI_PRIV_S3 | Setup S3 Buckets and configure settings |
| ISI_PRIV_S3_BUCKETS | S3 buckets and ACL |
| ISI_PRIV_S3_MYKEYS | S3 key management |
| ISI_PRIV_S3_SETTINGS | S3 global and zone settings |
| ISI_PRIV_S3_SETTINGS_GLOBAL | S3 global and service settings |
| ISI_PRIV_S3_SETTINGS_ZONE | S3 zone related settings |
| ISI_PRIV_SMB | Setup SMB Service, shares and configure settings |
| ISI_PRIV_SMB_SESSIONS | Active SMB sessions |
| ISI_PRIV_SMB_SETTINGS | View and manage SMB settings |
| ISI_PRIV_SMB_SETTINGS_GLOBAL | SMB global and service settings |
| ISI_PRIV_SMB_SETTINGS_SHARE | SMB filter and share Settings |
| ISI_PRIV_SMB_SHARES | SMB shares and permissions |
| ISI_PRIV_SWIFT | Configure Swift |
| ISI_PRIV_VCENTER | Configure VMware vCenter |
| ISI_PRIV_IFS_BACKUP | Backup files from /ifs |
| ISI_PRIV_IFS_RESTORE | Restore files to /ifs |
| ISI_PRIV_NS_TRAVERSE | Traverse and view directory metadata |
| ISI_PRIV_NS_IFS_ACCESS | Access /ifs via RESTful Access to Namespace service |
Additionally, two built-in roles are provided by default in a non-System access zone:
| Role | Description | Privilege |
| ZoneAdmin | Allows administration of aspects of configuration related to current access zone | · ISI_PRIV_LOGIN_PAPI
· ISI_PRIV_AUDIT · ISI_PRIV_FILE_FILTER · ISI_PRIV_HDFS · ISI_PRIV_NFS · ISI_PRIV_SMB · ISI_PRIV_SWIFT · ISI_PRIV_VCENTER · ISI_PRIV_NS_TRAVERSE · ISI_PRIV_NS_IFS_ACCESS |
| ZoneSecurityAdmin | Allows administration of aspects of security configuration related to current access zone | · ISI_PRIV_LOGIN_PAPI
· ISI_PRIV_AUTH · ISI_PRIV_ROLE |
Note that neither of these roles has any default users automatically assigned.
With RBAC, an authentication provider created from the System access zone can be viewed and used by all other access zones. However, it can only be modified/deleted from System access zone.
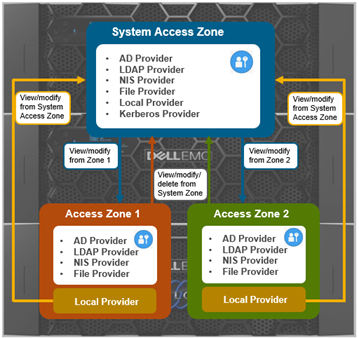
Be aware that a Kerberos provider can only be created from the System access zone.
With RBAC, an authentication provider created from a non-System access zone can only be used by that specific access zone. However, it can be administered (ie. viewed/modified/deleted) from either its access zone or the System access zone.
A local provider from a non-System access zone can only be used by that specific non-System access zone. It cannot be used by other access zones, including System access zone, and can only be viewed/modified from that specific non-system access zone and plus the system access zone.
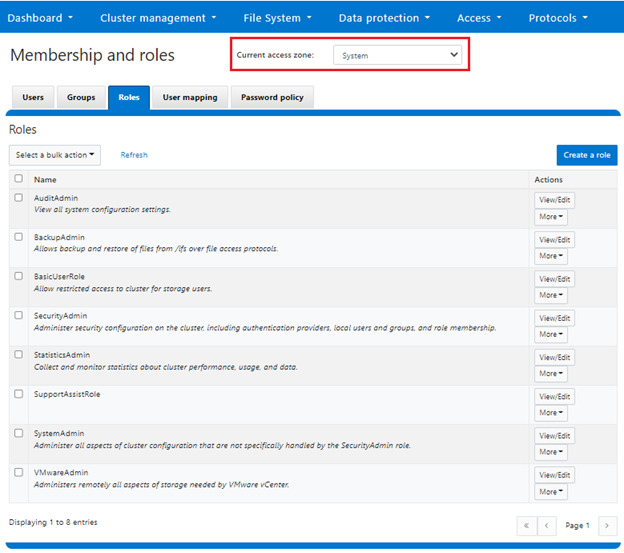
To support zone-aware RBAC, the OneFS WebUI includes a ‘current access zone’ field to select the desired zone. This is located under Access > Membership and Roles:
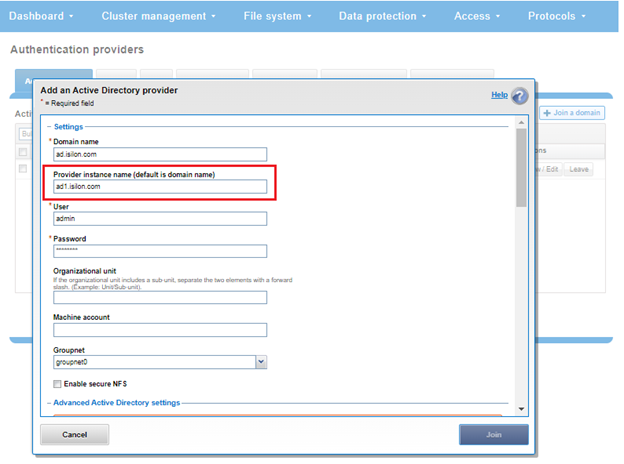
An ‘instance’ configuration field is used to identify specific AD authentication providers. There could be multiple AD authentication providers referring to a same domain and must specify an instance name and a machine account name
Each access zone’s administrator(s) can create their own AD authentication provider to connect to the same domain. This can be configured from either the WebUI or CLI command. However, each access zone can still only include a single AD authentication provider.
In the WebUI, the ‘instance name’ field appears under the ‘Add an Active Directory provider’ configuration screen, accessed by navigating to Access > Authentication Providers > Active Directory > Join a Domain:
Similarly, the ‘isi auth ads create’ CLI command sees the addition of ‘–instance’ and ‘–machine-account’ arguments. For example:
# isi auth ads create --name=ad.isilon.com --user=Administrator –-instance=ad1 –-machine-account=my-isilon123
The ‘instance’ name can then be used to reference the AD provider
# isi auth ads view ad1
To illustrate, take the following roles and privileges example. The smb2 role is created in zone2 and a user, smbuser2, added to the smb2 role:
# isi auth roles create --zone=zone2 smb2 # isi auth users create --zone=zone2 smbuser2 # isi auth roles modify smb2 --zone=zone2 --add-priv=ISI_PRIV_LOGIN_PAPI --add-priv=ISI_PRIV_SMB –-add-user=smbuser2 # isi auth roles modify smb2 --zone=zone2 --add-priv=ISI_PRIV_NETWORK Privilege ISI_PRIV_NETWORK cannot be added to role in non-System access zone # isi smb share create --zone=zone2 share2 /ifs/data/zone2 # isi_run -z zone2 -l smbuser2 isi smb shares list Share Name Path --------------------------- Share2 /ifs/data/zone2 --------------------------- Total: 1 # isi_run -z zone2 -l smbuser2 isi nfs exports list Privilege check failed. The following read privilege is required: NFS (ISI_PRIV_NFS)
As shown above, the smbuser2 can log into the WebUI via zone2 and can create/modify/view SMB shares/settings in zone2. Smbuser2 can also view, but not modify, global SMB configuration settings. However, Smbuser2 is not be able to view/modify shares in other zones.
When connecting to a cluster via the SSH session protocol to perform CLI configuration, be aware that SSH access is still only available from System access zone. As such, administrators coming from non-System access zones will only be able to use the WebUI or platform API to perform cluster configuration and management.
The ‘isi auth role’ CLI command offers a ‘–zone’ argument to report on specific access zones.:
# isi auth roles list -–zone=zone2
With no ‘–zone’ option specified, this command returns a list of roles in the current access zone.
Note that multiple instances connected to the same AD provider can be configured so long as each has a unique machine account name.
To help with troubleshooting permissions issues, the ‘isi_run’ CLI utility can be used to run OneFS CLI command(s) as if it were coming from a non-System zone. For example:
# isi_run -z zone2 isi auth roles list
Note that a zone name can be used as well as the zone ID as an argument for the -z (zone) flag option, as above.
In Kerberos environments, in order to work with AD, the appropriate service principal name (SPN) must be created in the appropriate Active Directory machine accounts, and duplicate SPNs must be avoided.
OneFS provides the ‘isi auth ads spn’ CLI command set to verify and manage SPN configuration. Command options include:
- Show which SPNs are missing or extra as compared to expected SPNs:
# isi auth ads spn check <AD-instance-name>
- Add and remove missing/extra SPNs:
# isi auth ads spn fix <AD-instance-name> --user=<Administrator>
- Add, but avoid removing extra SPNs:
# isi auth ads spn fix <AD-instance-name> --noremove
- Add an SPN, and add to ‘expected SPN’ list:
# isi auth ads spn create <AD-instance-name> <SPN>
- Delete an SPN and remove from ‘expected SPN’ list:
# isi auth ads spn delete <AD-instance-name> <SPN>