In contrast to many other storage appliances, PowerScale has always enjoyed an extensive, rich and capable command line, drawing from its FreeBSD heritage. As such, it incorporates a choice of full UNIX shells (ie. ZSH), the ability to script in a variety of languages (perl, python, etc), full data access, a variety of system and network management and monitoring tools, plus the comprehensive OneFS ‘isi’ command set. However, what is a bonus for usability can, on the flip side, also present a risk from a security point of view.
With this in mind, amongst the bevy of security features that debut in OneFS 9.5 release is the addition of a restricted shell for the CLI. This shell heavily curtails access to cluster command line utilities, eliminating areas where commands and scripts could be run and files modified maliciously and unaudited.
The new restricted shell can help both public and private sector organizations to meet a variety of regulatory compliance and audit requirements, in addition to reducing the security threat surface when administering OneFS.
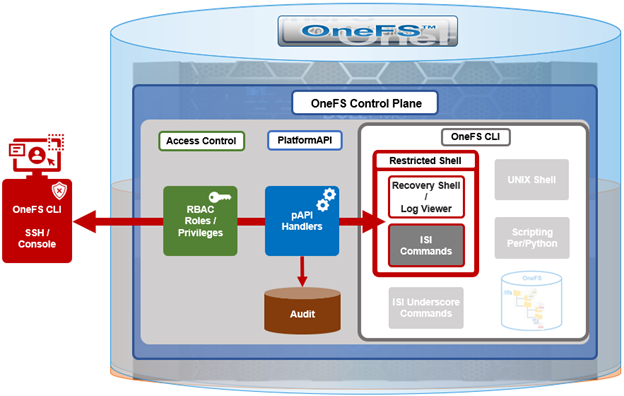
Written in python, the restricted shell constrains users to a tight subset of the commands available in the regular OneFS command line shells, plus a couple of additional utilities. These include:
| CLI Utility | Description |
| ISI commands | The ‘isi’ or ‘isi space’ commands. These include the commands such as ‘isi status’, etc. The full set of isi commands can are listed by ‘isi –help’ |
| Shell commands | The supported shell commands include ‘clear’, ‘exit’, ‘logout’, and ‘CTRL+D’. |
| Log access | The ‘isi_log_access’ tool can be used if the user possesses the ISI_PRIV_SYS_SUPPORT privilege. |
| Recovery shell | The recovery shell ‘isi_recovery_shell’ can be used if the users possesses the ISI_PRIV_RECOVERY_SHELL, and the security setting ‘Restricted shell Enabled’ is configured to ‘true’. |
In order for a OneFS CLI command to be audited, its handler needs to call through the platform API (pAPI). This occurs with the regular ‘isi’ commands, but not necessarily with the ‘isi underscore’ commands, such as ‘isi_for_array’, etc. While some of these ‘isi_*’ commands write to log files, there is no uniform or consistent auditing or logging.
On the data access side, /ifs file system auditing works through the various OneFS protocol heads (NFS, SMB, S3, etc). So if the CLI is used with an unrestricted shell to directly access and modify /ifs, any access and changes are unrecorded and unaudited.
In OneFS 9.5, the new restricted shell is included in the permitted shells list (/etc/shells):
# grep -i restr /etc/shells /usr/local/restricted_shell/bin/restricted_shell.py
It can be easily set for a user via the CLI. For example, to configure the ‘admin’ account to use the restricted shell, instead of its default of ZSH:
# isi auth users view admin | grep -i shell Shell: /usr/local/bin/zsh # isi auth users modify admin --shell=/usr/local/restricted_shell/bin/restricted_shell.py # isi auth users view admin | grep -i shell Shell: /usr/local/restricted_shell/bin/restricted_shell.py
OneFS can also be configured to limit non-root users to just the secure shell, too:
# isi security settings view | grep -i restr Restricted shell Enabled: No # isi security settings modify --restricted-shell-enabled=true # isi security settings view | grep -i restr Restricted shell Enabled: Yes
The underlying configuration changes to support this include only allowing non-root users with approved shells in /etc/shells to login via console or ssh and having just /usr/local/restricted_shell/bin/restricted_shell.py in the /etc/shells config file.
Note that no users’ shells are changed when the configuration commands above are enacted. If users are intended to have shell access, their login shell will need to be changed prior to them being able to login. Users will also require the privileges ‘ISI_PRIV_LOGIN_SSH’ and/or ‘ISI_PRIV_LOGIN_CONSOLE’ to be able to log in via SSH and the console respectively.
While the WebUI in OneFS 9.5 does not provide a secure shell configuration page, the restricted shell can be enabled from the platform API, in addition to the CLI. The pAPI security settings now include a ‘restricted_shell_enabled’ key which can be enabled by setting to value=1, from its default of ‘0’.
Be aware that, on configuring a OneFS 9.5 cluster to run in hardened mode with the STIG profile (ie. ‘isi hardening enable STIG’), the ‘restricted-shell-enable’ security setting is automatically set to ‘true’. This means that only root and users with ‘ISI_PRIV_LOGIN_SSH’ and/or ‘ISI_PRIV_LOGIN_CONSOLE’ privileges and the restricted shell as their shell will be permitted to login to the cluster. We will focus on OneFS security hardening in a future article.
So let’s take a look at some examples of the restricted shell’s configuration and operation. But note that a cluster’s default user ‘admin’ uses role-based access control (RBAC), whereas ‘root’ does not. As such, the ‘root’ account should ideally be as infrequently as possible, and ideally be considered solely as the account of last resort.
First, we log in as the ‘admin’ user and modify the ‘file’ and ‘local’ auth provider password hash types to the more secure ‘SHA512’ from their default value of ‘NTHash’:
# ssh 10.244.34.34 -l admin # isi auth file view System | grep -i hash Password Hash Type: NTHash # isi auth local view System | grep -i hash Password Hash Type: NTHash # isi auth file modify System –-password-hash-type=SHA512 # isi auth local modify System –-password-hash-type=SHA512
Note that a cluster’s default user ‘admin’ uses role-based access control (RBAC), whereas ‘root’ does not. As such, the ‘root’ account should ideally be as infrequently as possible, and ideally be considered solely as the account of last resort.
Next, the ‘admin’ and ‘root’ passwords are changed in order to generate new passwords using the SHA512 hash:
# isi auth users change-password root # isi auth users change-password admin
An ‘rl_ssh’ role is created and the SSH access privilege is added to it:
# isi auth roles create rl_ssh # isi auth roles modify rl_ssh –-add-priv=ISI_PRIV_LOGIN_SSH
Then a regular user (usr_ssh_restricted) and an admin user (usr_admin_resticted) are created with restricted shell privileges:
# isi auth users create usr_ssh_restricted –-shell=/usr/local/restricted_shell/bin/restricted_shell.py –-set-password # isi auth users create usr_admin_restricted –shell=/usr/local/restricted_shell/bin/restricted_shell.py –-set-password
We then assign the desired roles to the new users. For the restricted SSH user, we add to our newly created ‘rl_ssh’ role:
# isi auth roles modify rl_ssh –-add-user=usr_ssh_restricted
The admin user is then added to the security admin and the system admin roles:
# isi auth roles modify SecurityAdmin –-add-user=usr_admin_restricted # isi auth roles modify SystemAdmin –-add-user=usr_admin_restricted
Next, we connect to cluster via SSH and authenticate as the ‘usr_ssh_restricted’ user:
$ ssh usr_ssh_restricted@10.246.178.121 (usr_ssh_restricted@10.246.178.121) Password: Copyright (c) 2001-2023 Dell Inc. or its subsidiaries. All Rights Reserved. Copyright (c) 1992-2018 The FreeBSD Project. Copyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994 The Regents of the University of California. All rights reserved. PowerScale OneFS 9.5.0.0 Allowed commands are clear ... isi ... isi_recovery_shell ... isi_log_access ... exit logout %
This account has no cluster RBAC privileges beyond SSH access, so cannot run the various ‘isi’ commands. For example, attempting to run ‘isi status’ returns no data, instead warning of the need for event, job engine, and statistics privileges:
% isi status Cluster Name: h7001 *** Capacity and health information require *** *** the privilege: ISI_PRIV_STATISTICS. *** Critical Events: *** Requires the privilege: ISI_PRIV_EVENT. *** Cluster Job Status: *** Requires the privilege: ISI_PRIV_JOB_ENGINE. *** Allowed commands are clear ... isi ... isi_recovery_shell ... isi_log_access ... exit logout %
Similarly, standard UNIX shell commands, such as ‘pwd’ and ‘whoami’ are also prohibited:
% pwd Allowed commands are clear ... isi ... isi_recovery_shell ... isi_log_access ... exit logout % whoami Allowed commands are clear ... isi ... isi_recovery_shell ... isi_log_access ... exit logout
Indeed, without additional OneFS RBAC privileges, the only commands the ‘usr_ssh_restricted’ user can actually run in the restricted shell are ‘clear’, ‘exit’, and ‘logout’:
Note that the restricted shell automatically logs out an inactive session after a short period of inactivity.
Next, we log in in with the ‘usr_admin_restricted’ account:
$ ssh usr_admin_restricted@10.246.178.121 (usr_admin_restricted@10.246.178.121) Password: Copyright (c) 2001-2023 Dell Inc. or its subsidiaries. All Rights Reserved. Copyright (c) 1992-2018 The FreeBSD Project. Copyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994 The Regents of the University of California. All rights reserved. PowerScale OneFS 9.5.0.0 Allowed commands are clear ... isi ... isi_recovery_shell ... isi_log_access ... exit logout %
The ‘isi’ commands now work, since the user has the ‘SecurityAdmin’ and ‘SystemAdmin’ roles and privileges:
% isi auth roles list Name --------------- AuditAdmin BackupAdmin BasicUserRole SecurityAdmin StatisticsAdmin SystemAdmin VMwareAdmin rl_console rl_ssh --------------- Total: 9 Allowed commands are clear ... isi ... isi_recovery_shell ... isi_log_access ... exit logout % isi auth users view usr_admin_restricted Name: usr_admin_restricted DN: CN=usr_admin_restricted,CN=Users,DC=H7001 DNS Domain: - Domain: H7001 Provider: lsa-local-provider:System Sam Account Name: usr_admin_restricted UID: 2003 SID: S-1-5-21-3745626141-289409179-1286507423-1003 Enabled: Yes Expired: No Expiry: - Locked: No Email: - GECOS: - Generated GID: No Generated UID: No Generated UPN: Yes Primary Group ID: GID:1800 Name: Isilon Users Home Directory: /ifs/home/usr_admin_restricted Max Password Age: 4W Password Expired: No Password Expiry: 2023-05-30T17:16:53 Password Last Set: 2023-05-02T17:16:53 Password Expires: Yes Last Logon: - Shell: /usr/local/restricted_shell/bin/restricted_shell.py UPN: usr_admin_restricted@H7001 User Can Change Password: Yes Disable When Inactive: No Allowed commands are clear ... isi ... isi_recovery_shell ... isi_log_access ... exit logout %
However, the OneFS ‘isi underscore’ commands are not supported under the restricted shell. For example, attempting to use the ‘isi_for_array’ command:
% isi_for_array -s uname -a Allowed commands are clear ... isi ... isi_recovery_shell ... isi_log_access ... exit logout
Note that, by default, the ‘SecurityAdmin’ and SystemAdmin’ roles do not grant the ‘usr_admin_restricted’ user the privileges needed to execute the new ‘isi_log_access’ and ‘isi_recovery_shell’ commands.
In the next article in this series, we’ll take a look at these associated ‘isi_log_access’ and ‘isi_recovery_shell’ utilities that are also introduced in OneFS 9.5.