Unlike L1 and L2 cache, which are always present and operational in storage nodes, L3 cache is enabled per node pool via a simple on or off configuration setting. Other than this, there are no additional visible configuration settings to change. When enabled, L3 consumes all the SSD in node pool. Also, L3 cannot coexist with other SSD strategies, with the exception of Global Namespace Acceleration. However, since they’re exclusively reserved, L3 Cache node pool SSDs cannot participate in GNA.
Note that L3 cache is typically enabled by default on any new node pool containing SSDs.
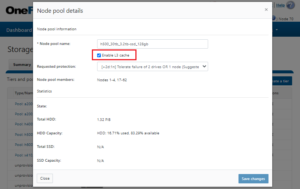
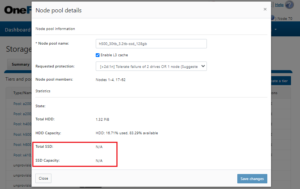
Once the SSDs have been reformatted and are under the control of L3 cache, the WebUI removes them from usable storage:
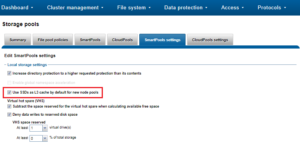
There is also a global setting which governs whether to enable L3 cache by default for new node pools.
When converting the SSDs in a particular nodepool to use L3 cache rather than SmartPools, progress can be estimated by periodically tracking SSD space (used capacity) usage over the course of the conversion process. Additionally, the Job impact policy of the Flexprotect_Plus or SmartPools job responsible for the L3 conversion can be reprioritized to run faster or slower. This has the effect of conversely increasing or decreasing the impact of the conversion process on cluster resources.
OneFS provides tools to accurately assess the performance of the various levels of cache at a point in time. These cache statistics can be viewed from the OneFS CLI using the isi_cache_stats command. Statistics for L1, L2 and L3 cache are displayed for both data and metadata.
# isi_cache_stats Totals l1_data: a 446G 100% r 579G 85% p 134G 89%, l1_encoded: a 0.0B 0% r 0.0B 0% p 0.0B 0%, l1_meta: r 82T 100% p 219M 92%, l2_data: r 376G 78% p 331G 81%, l2_meta: r 604G 96% p 1.7G 4%, l3_data: r 6G 19% p 0.0B 0%, l3_meta: r 24G 99% p 0.0B 0%
For more detailed and formatted output, a verbose option of the command is available using the ‘isi_cache_stats -v’ option:
# isi_cache_stats -v ------------------------- Totals ------------------------- l1_data: async read (8K blocks): aread.start: 58665103 / 100.0% aread.hit: 58433375 / 99.6% aread.miss: 231378 / 0.4% aread.wait: 350 / 0.0% read (8K blocks): read.start: 89234355 / 100.0% read.hit: 58342417 / 65.4% read.miss: 13082048 / 14.7% read.wait: 246797 / 0.3% prefetch.hit: 17563093 / 19.7% prefetch (8K blocks): prefetch.start: 19836713 / 100.0% prefetch.hit: 17563093 / 88.5% l1_encoded: async read (8K blocks): aread.start: 0 / 0.0% aread.hit: 0 / 0.0% aread.miss: 0 / 0.0% aread.wait: 0 / 0.0% read (8K blocks): read.start: 0 / 0.0% read.hit: 0 / 0.0% read.miss: 0 / 0.0% read.wait: 0 / 0.0% prefetch.hit: 0 / 0.0% prefetch (8K blocks): prefetch.start: 0 / 0.0% prefetch.hit: 0 / 0.0% l1_meta: read (8K blocks): read.start: 11030213475 / 100.0% read.hit: 11019567231 / 99.9% read.miss: 8070087 / 0.1% read.wait: 2548102 / 0.0% prefetch.hit: 28055 / 0.0% prefetch (8K blocks): prefetch.start: 30483 / 100.0% prefetch.hit: 28055 / 92.0% l2_data: read (8K blocks): read.start: 63393624 / 100.0% read.hit: 5916114 / 9.3% read.miss: 4289278 / 6.8% read.wait: 9815412 / 15.5% prefetch.hit: 43372820 / 68.4% prefetch (8K blocks): prefetch.start: 53327065 / 100.0% prefetch.hit: 43372820 / 81.3% l2_meta: read (8K blocks): read.start: 82823463 / 100.0% read.hit: 78959108 / 95.3% read.miss: 3643663 / 4.4% read.wait: 1758 / 0.0% prefetch.hit: 218934 / 0.3% prefetch (8K blocks): prefetch.start: 5517237 / 100.0% prefetch.hit: 218934 / 4.0% l3_data: read (8K blocks): read.start: 4418424 / 100.0% read.hit: 817632 / 18.5% read.miss: 3600792 / 81.5% read.wait: 0 / 0.0% prefetch.hit: 0 / 0.0% prefetch (8K blocks): prefetch.start: 0 / 0.0% prefetch.hit: 0 / 0.0% l3_meta: read (8K blocks): read.start: 3104472 / 100.0% read.hit: 3087217 / 99.4% read.miss: 17255 / 0.6% read.wait: 0 / 0.0% prefetch.hit: 0 / 0.0% prefetch (8K blocks): prefetch.start: 0 / 0.0% prefetch.hit: 0 / 0.0% l1_all: prefetch.start: 19867196 / 100.0% prefetch.misses: 0 / 0.0% l2_all: prefetch.start: 58844302 / 100.0% prefetch.misses: 48537 / 0.1%
It’s worth noting that for L3 cache, the prefetch statistics will always read zero, since it’s a pure eviction cache and does not utilize data or metadata prefetch.
Due to balanced data distribution, automatic rebalancing, and distributed processing, OneFS is able to leverage additional CPUs, network ports, and memory as the system grows. This also allows the caching subsystem (and, by virtue, throughput and IOPS) to scale linearly with the cluster size.