Prior to SmartThrottling, the native Job Engine resource monitoring and processing framework has allowed jobs to be throttled based on both CPU and disk I/O metrics. This legacy process still operates in OneFS 9.8 when SmartThrottling is not running. The coordinator itself does not communicate directly with the worker threads, but rather with the director process, which in turn instructs a node’s manager process for a particular job to cut back threads.
For example, if the Job Engine is running a job with LOW impact and CPU utilization drops below the threshold, the worker thread count is gradually increased up to the maximum defined by the LOW impact policy threshold. If client load on the cluster suddenly spikes, the number of worker threads is gracefully decreased. The same principle applies to disk I/O, where the Job Engine throttles back in relation to both IOPS as well as the number of I/O operations waiting to be processed in any drive’s queue. Once client load has decreased again, the number of worker threads is correspondingly increased to the maximum LOW impact threshold.
Every 20 seconds, the coordinator process gathers cluster CPU and individual disk I/O load data from all the nodes across the cluster. The coordinator uses this information, in combination with the job impact configuration, to determine how many threads may run on each cluster node to service each running job. This number can be fractional, and fractional thread counts are achieved by having a thread sleep for a given percentage of each second.
Using this CPU and disk I/O load data, every 60 seconds the coordinator evaluates how busy the various nodes are and makes a job throttling decision, instructing the various Job Engine processes as to the action they need to take. This enables throttling to be sensitive to workloads in which CPU and disk I/O load metrics yield different results. Additionally, separate load thresholds are tailored to the different classes of drives used in OneFS powered clusters, including high-speed SAS drives, lower-performance SATA disks, and flash-based solid state drives (SSDs).
The Job Engine allocates a specific number of threads to each node by default, thereby controlling the impact of a workload on the cluster. If little client activity is occurring, more worker threads are spun up to allow more work, up to a predefined worker limit. For example, the worker limit for a LOW impact job might allow one or two threads per node to be allocated, a MEDIUM impact job from four to six threads, and a HIGH impact job a dozen or more. When this worker limit is reached (or before, if client load triggers impact management thresholds first), worker threads are throttled back or terminated.
For example, a node has four active threads, and the coordinator instructs it to cut back to three. The fourth thread is allowed to finish the individual work item it is currently processing, but then quietly exit, even though the task as a whole might not be finished. A restart checkpoint is taken for the exiting worker thread’s remaining work, and this task is returned to a pool of tasks requiring completion. This unassigned task is then allocated to the next worker thread that requests a work assignment, and processing continues from the restart checkpoint. This same mechanism applies in the event that multiple jobs are running simultaneously on a cluster.
In contrast to this legacy job Engine impact management process, SmartThrottling instead draws its metrics from the OneFS Partitioned Performance (PP) framework. This framework is the same telemetry source that SmartQoS uses to limit client protocol operations.
Under the hood, SmartThrottling operates as follows:
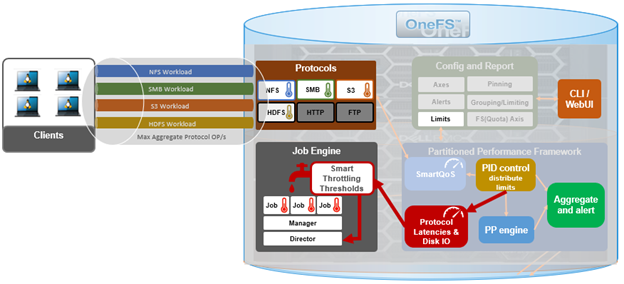
- First, Partitioned Performance directly monitors the cluster resource usage at the IRP layer, paying attention to the latencies of the critical client protocol load.
- Based on these PP metrics, the Job Engine then attempts to maintain latencies within a specified threshold.
- If they approach the configured upper bound, PP directs the Job Engine to stop increasing the amount of work performed.
- If the latencies exceed those thresholds, then the Job Engine actively reduces the amount of work performed by quiescing job worker threads as necessary.
- There’s also a secondary throttling mechanism for situations when no protocol load exists, to prevent the Job Engine from commandeering all the cluster resources. This backup throttling monitors the drives, just in case there’s something else going on that’s causing the disks to become overloaded – and similarly attempts to maintain disk IO health within set limits.
The SmartThrottling thresholds, and the rate of ramping up or down the amount of work, differs based on the impact setting of a specific job. The actual Job impact configuration remains unchanged from earlier releases, and can still be set to Low, Medium, or High. And each job still has the same default impact level and priority, which can be further adjusted if desired.
Note that, since the new SmartThrottling is a freshly introduced feature at this point, it is currently disabled by default in OneFS 9.8 in an abundance of caution. So it needs to be manually enabled if you want it to run.
In the next article in this series, we’ll dig into the details of configuring and managing SmartThrotting.